
Fundamentos de Manutenção de Software
2 Código Limpo 🔗
Programs must be written for people to read, and only incidentally for machines to execute. ― Harold Abelson (Structure and Interpretation of Computer Programs, 1984)
Este capítulo começa apresentando motivos e justificativas para a escrita de código legível e de fácil compreensão (Seção 2.1). Depois, na Seção 2.2, comentamos sobre a importância da adoção sistemática de guias para escrita de código legível, conhecidos também como guias de estilo. Na Seção 2.3, abordamos a importância do uso de ferramentas para verificar guias de estilo. Em seguida, na Seção 2.4, apresentamos recomendações para a escrita de nomes de identificadores que sejam claros e expressivos. Também descrevemos boas práticas para facilitar a compreensão de código, tais como evitar o uso de números mágicos (Seção 2.5) e adotar uma linguagem ubíqua (Seção 2.6). Já na Seção 2.7, apresentamos recomendações para escrita de funções legíveis e de fácil entendimento. Terminamos o capítulo com uma seção sobre tratamento de exceções (Seção 2.8), enfatizando a importância de projetar bem essa parte do código, sempre de forma a facilitar seu entendimento e legibilidade.
2.1 Introdução 🔗
Software, em última instância, é um conjunto de linhas de código. Por isso, código é um ativo central em empresas digitais, incluindo bancos, redes sociais, sites de comércio eletrônico, serviços de streaming, etc. Código também apoia cada vez mais as empresas do mundo físico, como indústrias automobilísticas, petrolíferas, mineradoras, etc. Em síntese, qualquer empresa atualmente deve cuidar da sua base de código. E tal cuidado começa na escrita de cada linha!
Especificamente, existe uma grande chance de que o código escrito hoje seja lido por anos, por um variado número de desenvolvedores, conforme já comentamos no Capítulo 1. Logo, é fundamental escrever código que seja legível para os outros, conforme recomenda também o Prof. Harold Abelson, na citação que abre o capítulo.
Vamos fazer uma conta rápida para justificar esse ponto. Suponha que você levou 3 horas para escrever um determinado trecho com 100 linhas de código. Porém, você fez isso de forma apressada e seu código ficou ilegível. Mas se tivesse investido uma hora a mais você conseguiria escrever um código com excelente legibilidade! Suponha ainda que, depois de escrito, a leitura e entendimento do seu código por terceiros vai levar 30 minutos. Porém, esse tempo diminuiria 10% se tivesse investido a hora extra para ter uma implementação otimizada para leitura e compreensão. Suponha ainda que esse código tenha que ser mantido duas vezes por mês, durante 10 anos. Logo, serão 240 manutenções e a economia conseguida com o código legível será de 240 x 3 minutos = 720 minutos = 12 horas. Ou seja, uma hora de investimento proporcionou em 10 anos uma economia de 12 horas.
Porém, essa economia é muito maior, pois sistemas têm milhões de linhas de código. Vamos supor um sistema com 1 MLOC, ou seja, 10 mil potenciais trechos de código com 100 LOC. Para ser mais realista, suponha que só metade deles vai precisar ser modificado na frequência desse exemplo. Logo, a economia passaria a ser de 5 mil x 12 horas = 60 mil horas ou, aproximadamente, 7 anos ininterruptos de trabalho.
Claro, esses números são hipotéticos e, portanto, sujeitos a questionamentos. Porém, na essência, eles ilustram que — quando consideramos o tempo de vida e o tamanho de um sistema — escrever código que seja legível traz uma economia relevante. As grandes empresas de tecnologia, de forma deliberada ou mesmo intuitiva, já chegaram também a essa conclusão. Por isso, elas tratam suas bases de código com muito critério, começando pela adoção sistemática de padrões para escrita de código legível, como estudaremos neste capítulo.
Por outro lado, é importante mencionar que outras práticas também ajudam a melhorar a manutenibilidade de uma base de código. Podemos citar, por exemplo, a adoção de bons princípios e padrões de projeto e também de uma arquitetura que facilite mudanças e a implementação de testes. Porém, neste livro, vamos focar em práticas que ajudam na escrita de código legível, porque achamos que elas são mais básicas, possuindo aplicação imediata mesmo que você seja um desenvolvedor júnior que ficou encarregado de escrever poucas linhas de código.
2.2 Adote um Guia de Estilo 🔗
No caso de código, guias de estilo (style guides) definem
regras para escrita, indentação, formatação e organização do código.
Normalmente, eles são definidos para uma linguagem de programação
específica. Ou seja, se uma empresa usa múltiplas linguagens, ela deve
usar um guia para cada uma delas. Por isso, os guias de estilo também
podem incluir regras de programação. Por exemplo, um guia pode proibir o
uso de operadores ternários, tal como em
min = (x < y) ? x : y.
A adoção de um guia de estilo tem como objetivo melhorar a
legibilidade do código, garantindo que ele seja claro, fácil de entender
e consistente. Consequentemente, esses guias fazem com que os
desenvolvedores se acostumem com a formatação do código e possam gastar
suas energias apenas no entendimento da lógica do programa que estão
mantendo. Além disso, a adoção de um guia de estilo ajuda os
desenvolvedores a se sentirem em casa
quando têm que manter um
código desenvolvido por um outro desenvolvedor. Isso é importante para
garantir a longevidade de um sistema que está sendo mantido por centenas
de desenvolvedores ao longo de anos. Assim, a adoção de tais guias, de
forma sistemática e com poucas exceções, é uma prática comum em empresas
que prezam pela qualidade de seus sistemas.
No entanto, na maioria das vezes, uma empresa não precisa criar um guia de estilo do zero. Em vez disso, ela pode usar guias propostos por grandes empresas de tecnologia, tais como Oracle, Google ou Airbnb. Pode-se usar também guias definidos pelos próprios criadores de uma linguagem de programação, como ocorre com Python ou Go; ou pelos desenvolvedores de projetos de código aberto, como GNU ou Linux.
Exemplo 1: Neste capítulo, não vamos descrever um guia de estilo por completo, pois isso seria cansativo e repetiria conteúdo que está público na Web. Porém, para ilustrar, vamos comentar sobre algumas regras do guia de estilo para Java proposto pelo Google (link).
Segundo esse guia, chaves de abertura de bloco devem ficar na mesma linha do comando a que se referem e devem ser seguidas de uma quebra de linha (veja as linhas 1, 2 e 3 do exemplo abaixo); chaves de fechamento também são seguidas de uma quebra de linha (linhas 5-7). Além disso, devemos usar chaves mesmo quando elas delimitam um único comando (linhas 3-5). Níveis de indentação de blocos são uma outra recomendação levada a sério em guias de estilo. Segundo o guia que estamos usando como exemplo, cada nível de indentação implica um avanço de dois espaços para a direita (linhas 2, 3 e 4).
1: public class MinhaClasse {
2: public void meuMetodo(String[] args) {
3: for (int i = 1; i <= 5; i++) {
4: IO.println("Contador: " + i);
5: }
6: }
7: }Outras regras importantes e que também devem ser seguidas dizem
respeito ao uso de espaços. Por exemplo, sempre deve existir um espaço
entre um comando de controle (exemplo: for) e o parêntese
que segue o nome do comando (linha 3). Porém, no cabeçalho ou na chamada
de um método, não há espaço antes do parêntese que abre a lista de
parâmetros (linhas 2 e 4).
Guias de estilo também podem incluir boas práticas de programação.
Por exemplo, o guia de estilo para Java do Google recomenda usar
@Override em métodos que redefinem um método de uma
superclasse ou que implementam um método de uma interface. Como outro
exemplo, ele recomenda que o acesso a membros estáticos deve ser sempre
qualificado com o nome da classe do membro, tal como no seguinte exemplo
(adaptado do guia de estilo em questão).
1: Foo aFoo = ...;
2: Foo.umMetodoEstatico(); // ok
3: aFoo.umMetodoEstatico(); // nok
4: umOutroMetodoQueRetornaFoo().umMetodoEstatico(); // nokEsse exemplo é interessante porque as três chamadas de método (linhas
2 a 4) compilam sem erros em Java. Ou seja, guias de estilo são usados
para impor restrições extras àquelas definidas pela sintaxe de uma
linguagem, com o objetivo de melhorar a legibilidade do seu código. Na
primeira chamada do exemplo, fica evidente que
umMetodoEstatico é implementado na classe Foo.
Já nas outras duas chamadas, isso é menos evidente e, portanto, o leitor
do código tem que fazer um pouco mais de esforço para descobrir a classe
do método estático.
Exemplo 2: Nesta seção, estamos tratando de guias de estilo para código. Mas existem guias também para escrita e formatação de texto em português. Por exemplo, alguns jornais brasileiros possuem Manuais de Redação. Um outro exemplo são as normas da ABNT para escrita de textos acadêmicos. Para a língua inglesa, há referências clássicas como o The Chicago Manual of Style. Em essência, esses documentos complementam a gramática de uma língua com recomendações para organização e estruturação de texto.
Mundo Real: Algumas vezes até como parte de
brincadeiras, desenvolvedores gostam de debater se devem indentar blocos
de código com tabs ou espaços. Porém, os guias de estilo mais conhecidos
sugerem o uso de espaços, como é o caso do Guia de Estilo para Java do
Google e também da Oracle e o Guia de Estilo PEP 8, para Python. Uma
vantagem de usar espaço é que o código será sempre exibido da mesma
forma, independentemente do editor ou IDE. Por outro lado, outros
desenvolvedores consideram que isso, na verdade, é uma desvantagem.
Segundo eles, tabs são melhores exatamente por permitir que se
personalize o nível de indentação do editor, isto é, o número de espaços
produzidos por um tab. De todo modo, como sempre reforçamos nesta seção,
a melhor decisão consiste em seguir um guia de estilo que seja conhecido
e amplamente usado (e não questionar tais detalhes
).
2.2.1 Adote um Estilo de Nomes 🔗
Guias de estilo definem também regras para escrita de nomes de identificadores com mais de uma palavra. Nesses casos, os estilos mais comuns são descritos a seguir.
camelCase: Também conhecido como
lowerCamelCase, este estilo define que a primeira palavra de um
identificador deve ser escrita em minúsculo e a primeira letra das
demais palavras em maiúsculo. Por exemplo, o guia de estilo para Java
que usamos como exemplo define que nomes de identificadores, exceto
classes, devem ser escritos em camelCase, tal como em
atualizarStatusPedido. O nome camelCase deriva do aspecto
resultante dos nomes, que lembra as corcovas de um camelo devido às
subidas e descidas da capitalização das letras.
PascalCase: Também conhecido como
UpperCamelCase, este estilo é idêntico a camelCase, porém a
primeira letra também é escrita em maiúsculo. Nomes de classes, em Java,
costumam seguir esse estilo, como em CarrinhoDeCompras.
snake_case: Também conhecido como
underscore_case, neste estilo as palavras de um identificador
são unidas por um caractere de sublinhado, como em
quantidade_estoque e data_pedido. Ele é muito
usado em nomes de variáveis e métodos, em linguagens como Python, Ruby,
C, C++ e Elixir.
UPPER_SNAKE_CASE (ou SCREAMING_SNAKE_CASE): Neste
estilo, todas as letras são escritas em maiúsculas e separadas por um
underscore. Muito usado para constantes, como em
MAX_SIZE.
Literatura Científica: Diversos estudos já investigaram qual estilo de nomes é mais efetivo. Um exemplo interessante foi um estudo abrangente coordenado por Dave Binkley, da Loyola Maryland University (EUA) e colegas (link). Nele, participantes foram instruídos a marcar todas as linhas de um trecho de código que continham um determinado identificador. Para alguns participantes, o código foi escrito usando camelCase; para outros, em snake_case. Em outro estudo (link), conduzido por Bonita Sharif e Jonathan Maletic, da Kent State University (EUA), câmeras especiais para rastreamento ocular foram usadas para medir a posição da pupila e os pontos de fixação do olhar dos participantes. O objetivo foi ter uma aproximação do esforço cognitivo necessário para ler um trecho de código. Porém, ambos os estudos não indicaram a superioridade inequívoca de um estilo sobre outro e os resultados, no geral, foram semelhantes. Na verdade, as diferenças foram ainda menores quando os participantes tiveram algum contato prévio com o estilo avaliado. Por isso, o mais importante é seguir um estilo de nomes, seja ele recomendado por uma organização ou pelos criadores de uma linguagem de programação. O estilo em si não é o mais importante, mas o seu uso de forma consistente e sistemática.
2.2.2 Perguntas Frequentes 🔗
Existem exceções que justificam não seguir uma determinada regra de um guia de estilo? Tipicamente, as regras de um guia de estilo devem ser seguidas de forma rigorosa. Porém, sempre existem exceções. Por exemplo, você pode estar mantendo um programa antigo, que foi desenvolvido antes da sua empresa adotar um certo guia de estilo. Se esse programa for importante e muito modificado, pode ser interessante adaptá-lo para usar o estilo em vigor. Porém, se ele implementar uma funcionalidade que raramente precisa ser mantida, talvez o melhor seja não investir nessa adaptação.
As regras de um guia de estilo podem evoluir? Sim, isso acontece inclusive com os estilos mais conhecidos do mercado. Até porque as próprias linguagens de programação também evoluem. No entanto, a decisão de migrar para uma nova versão de um guia de estilo deve ser tomada com cuidado, pois ela pode impactar toda a base de código da organização. Por outro lado, algumas decisões têm menos impacto no código existente, como, por exemplo, proibir o uso de um recurso novo de uma linguagem de programação. Nesse caso, a justificativa pode ser porque esse recurso ainda não está maduro ou não é do domínio de todos os desenvolvedores da organização.
2.3 Use Verificadores de Estilo e Formatadores 🔗
Existem também ferramentas que verificam automaticamente se um código segue um determinado guia de estilo. Assim, evita-se que essa verificação seja feita de forma manual, por exemplo, durante um processo de revisão de código. Também é comum que essas ferramentas sejam executadas por servidores de integração contínua, antes da revisão manual do código. Assim, os revisores não têm que verificar se o código que será integrado segue o estilo definido pela empresa, pois essa verificação foi automatizada.
Exemplo: Considere uma versão modificada do exemplo anterior.
1: public class minhaClasse {
2: public void meuMetodo(String[] args) {
3: for (int i = 1; i <= 5; i++)
4: IO.println ("Contador: " + i);
5: }
6: }A ferramenta Checkstyle é um verificador de estilos popular em projetos que usam Java. Quando o Checkstyle é usado no código acima, ele gera os seguintes avisos:
[WARN] line 1:14: Type name 'minhaClasse' must match
pattern '^[A-Z][a-zA-Z0-9]*$'.
[WARN] line 3:5: 'for' construct must use '{}'s.
[WARN] line 4:18 '(' is preceded with whitespace. Ou seja, a ferramenta recomenda corretamente que o nome da classe
deve começar com uma letra maiúscula; que o corpo do for
deve ser delimitado por chaves; e que existe um espaço a mais após o
IO.println e antes do parênteses abrindo.
Um outro tipo de ferramenta útil são os formatadores de código, isto é, ferramentas que formatam automaticamente um programa para atender a um certo guia de estilo. Um exemplo é a ferramenta de formatação que faz parte da linguagem Go. Por ser nativa e oficial da linguagem, seu uso é muito comum entre desenvolvedores de Go. Elixir é uma outra linguagem que oferece um formatador de código nativo.
Formatadores e ferramentas de verificação de estilo também podem ser combinados. Pode-se usar um formatador localmente, na máquina do desenvolvedor, e depois um verificador de estilo pode ser executado pelo servidor de Integração Contínua, para fazer uma verificação final, antes de o código ser integrado no repositório principal do projeto.
2.4 Escolha Nomes Legíveis 🔗
Na seção anterior, comentamos sobre a importância de padronizar um estilo para nomes compostos, seja ele camelCase, PascalCase ou underscore_case. Porém, esses estilos definem como concatenar nomes formados por mais de uma palavra. Ou seja, eles não especificam como tais nomes devem ser escolhidos.
A escolha de nomes claros para variáveis, métodos, classes, exceções e demais elementos de um programa é um dos aspectos mais importantes para a produção de código legível. No entanto, sabemos que essa não é uma tarefa trivial, pois exige disciplina, capricho, prática e conhecimento do domínio de um sistema. Existe inclusive uma frase provocativa que diz que a escolha de bons nomes é um dos problemas mais desafiadores em computação!
Na verdade, é fácil entender por que bons nomes são fundamentais para a compreensão de um programa. Por exemplo, sejam duas versões de um mesmo programa:
Versão 1 (nomes abreviados ou genéricos):
class C {
private double s;
public C(double s) {
this.s = s;
}
public void sac(double x) {
this.s = this.s - x;
}
public void dep(double y) {
this.s = this.s + y;
}
}
Versão 2 (nomes completos):
class ContaBancaria {
private double saldo;
public ContaBancaria(double saldo) {
this.saldo = saldo;
}
public void sacar(double valor) {
this.saldo = this.saldo - valor;
}
public void depositar(double valor) {
this.saldo = this.saldo + valor;
}
}Mesmo nesse programa simples, é mais fácil entender a segunda versão
do que a primeira, pois nomes como ContaBancaria,
saldo, valor, sacar e
depositar transmitem claramente o seu propósito no código.
O mesmo não acontece com nomes abreviados ou genéricos, como
C, s, x, y,
sac e dep.
Para generalizar, existe uma regra geral para seleção de bons nomes, que é a seguinte:
Nomes devem revelar claramente seu propósito no código.
Essa regra geral pode ser detalhada nas seguintes regras específicas:
1. Não economize caracteres para abreviar nomes de identificadores.
Em vez disso, use nomes tal como eles aparecem em um dicionário. Por
exemplo, saldo é melhor do que apenas s. Isso
vai facilitar também pesquisas por código que usa um determinado
identificador.
2. No entanto, abreviaturas e siglas conhecidas são permitidas. Como
exemplo, podemos citar um método chamado getURL() ou uma
classe chamada ServidorHTTP.
3. Se necessário, use nomes compostos por mais de uma palavra, mas
respeitando as regras de concatenação de nomes (camelCase, PascalCase,
underscore_case, etc.). Por exemplo, nomeUsuario e
idUsuario são melhores do que apenas nome e
id. De forma semelhante, totalAlunos é melhor
do que apenas total.
4. Quanto mais amplo o escopo de uma variável, maior deve ser o seu
tamanho em caracteres. Por exemplo, contadores de loops costumam ter
nomes com apenas uma letra, como i, j e
k, já que o corpo de um loop possui poucas linhas de
código. Por outro lado, variáveis globais, quando imprescindíveis em um
sistema, devem ter nomes mais extensos e descritivos, como
taxaRetencaoClientesVIP ou
totalAnualArtigosCompletosPublicados.
5. Nomes de classes devem ser substantivos, simples ou compostos,
como em: Pilha, ListaEncadeada,
Cliente, Pessoa e
ServicoPagamento.
6. Evite nomes genéricos para classes, como Dados,
Resultados ou Gerenciador.
7. Nomes de funções devem começar com um verbo, tal como em:
sacar, depositar, empilhar,
enviarMensagem, calcularFrete, etc.
8. Funções que retornam valores booleanos devem ter um nome que deixe
isso claro, tal como: isAvailable(),
hasNext(), canLogin(), etc. Aqui, preferimos
usar nomes em inglês, mas, claro, eles podem ser em português
também.
9. Evite nomes que neguem uma condição. Por exemplo, em vez de
isNotEmpty() prefira chamar uma função de
hasItems().
Nota: Nos exemplos acima, usamos camelCase, mas a mesma ideia vale para linguagens e guias de estilo que recomendam o uso de underscore_case.
Literatura Científica: Em 2005, Florian Deißenbock e Markus Pizka, da Universidade Técnica de Munique, realizaram uma análise sobre o uso de identificadores em um grande sistema Java, com mais de 2 MLOC (link). Os autores mostraram que mais de 70% dos caracteres presentes no código fonte desse sistema são referentes a nomes de identificadores. Logo, esse resultado reforça a importância de escolher nomes expressivos para identificadores, pois eles são parte majoritária do código fonte. Em 2017, um outro estudo interessante foi realizado por Johannes Hofmeister, Janet Siegmund e Daniel V. Holt, também pesquisadores de universidades alemãs (link). Nesse estudo, 72 desenvolvedores foram instruídos a corrigir bugs em programas C# que implementam algoritmos simples. Foram geradas três versões desses programas: com identificadores formados por palavras completas, por abreviações com apenas três letras e com letras únicas. Quando apresentados a um programa cujos identificadores eram palavras completas, os participantes conseguiram detectar 19% a mais de bugs por unidade de tempo do que nas versões com nomes abreviados ou com uma única letra.
2.5 Evite Números Mágicos 🔗
Números mágicos são valores que aparecem no código sem contexto ou explicação sobre seu propósito. Por isso, recomenda-se usar constantes no lugar de tais números. Isso facilita o entendimento do código e também a adaptação do programa caso o número mágico precise ser alterado.
Para ilustrar o uso de constantes no lugar de números mágicos, considere o seguinte programa:
double calculaPrecoFinal(double preco, double peso) {
double frete;
if (peso <= 1.5) {
frete = 0.315 * peso;
} else {
frete = 0.378 * peso;
}
return preco * 1.18 + frete;
}Considere agora uma nova versão, na qual os números mágicos foram substituídos por constantes.
static final double LIMITE_PESO = 1.5;
static final double FRETE_BASICO = 0.315;
static final double FRETE_ESPECIAL = 0.378;
static final double ALIQUOTA_ICMS = 1.18;
double calculaPrecoFinal(double preco, double peso) {
double frete;
if (peso <= LIMITE_PESO) {
frete = FRETE_BASICO * peso;
} else {
frete = FRETE_ESPECIAL * peso;
}
return preco * ALIQUOTA_ICMS + frete;
}O segundo código é mais legível, pois ele deixa claro que existem dois tipos de frete (básico e especial) e que o incremento de 18% no preço deve-se à cobrança de ICMS.
O uso de uma constante é ainda mais vantajoso quando o número mágico aparece em diversas linhas de código. Nesse caso, quando se usa uma constante, uma alteração no seu valor requer alterar apenas a linha que define a constante.
Constantes devem ser definidas o mais próximo possível da entidade de código na qual são usadas. Ou seja, se uma constante somente é usada em uma função, ela deve ser definida nessa função. Se ela precisa ser usada em uma classe, ela deve ser um atributo privado e final dessa classe.
Assim, considera-se um antipadrão declarar todas as constantes do sistema em uma única classe global. Essa classe tende a crescer de tamanho e misturar constantes com propósitos diferentes. Além disso, elas vão ter visibilidade global no sistema, o que nem sempre seria necessário.
2.6 Adote uma Linguagem Ubíqua 🔗
Linguagem ubíqua é um dos conceitos centrais de Domain-Driven Design (DDD), que, por sua vez, é um conjunto de princípios de projeto proposto por Eric Evans em um livro de mesmo nome.
Apesar do nome complexo, a ideia de uma linguagem ubíqua é simples. De acordo com Evans, a linguagem ubíqua consiste no conjunto de nomes que devem ser plenamente entendidos tanto por especialistas no domínio de um sistema (tais como certos usuários) como por seus desenvolvedores. Em outras palavras, DDD defende que esses dois papéis — especialistas no domínio e desenvolvedores — devem falar a mesma língua, que vai constituir a linguagem ubíqua do sistema.
A ideia de uma linguagem ubíqua, normalmente, é ilustrada por meio da figura da próxima página. Ela deixa claro que existem nomes que somente os especialistas de domínio conhecem. Já outros nomes, de cunho técnico, são do conhecimento apenas dos desenvolvedores. Porém, existe um conjunto de nomes que deve ser do conhecimento de ambos, os quais formam a linguagem ubíqua do sistema.
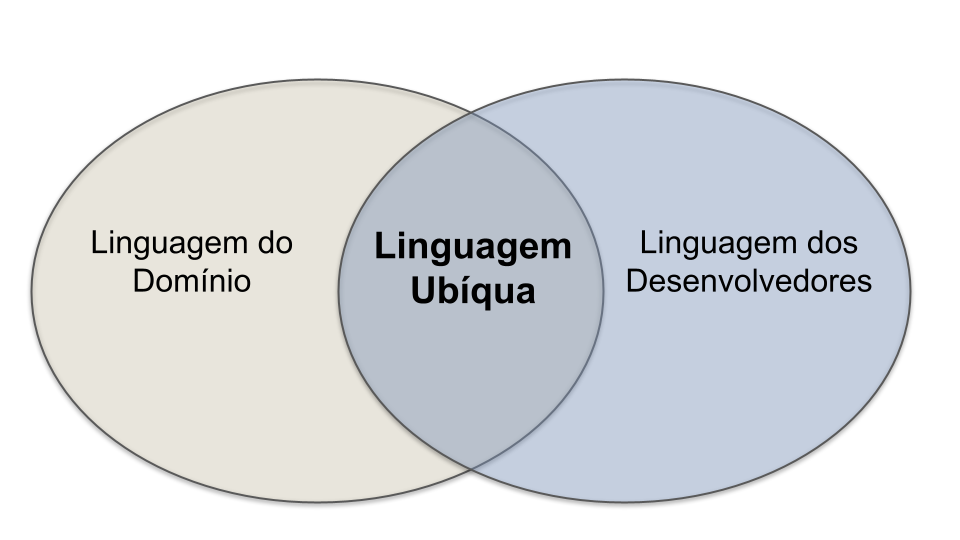
Os nomes da linguagem ubíqua são usados com dois propósitos: (1) para possibilitar uma comunicação fluida e livre de ruídos entre desenvolvedores e especialistas no domínio; (2) para nomear entidades do código do sistema, tais como classes, métodos, atributos, pacotes, tabelas de bancos de dados, rotas de APIs, etc.
Exemplo: Suponha um sistema para gerenciamento de bibliotecas. A linguagem ubíqua desse sistema inclui nomes como os seguintes:
Livro, Exemplar, ISBN, Bibliotecária, Usuário, Acervo, Reserva, Empréstimo, Multa, Catálogo
Por outro lado, alguns nomes são de domínio apenas dos desenvolvedores, tais como proxy, cache, camadas, rotas, dentre outros. Existem ainda outros nomes que são do conhecimento apenas de bibliotecárias, como formatos para identificadores de livros usados apenas em alguns países.
Glossário de Nomes: Alguns autores recomendam que todo projeto de software deve ter um glossário de nomes, mesmo que simples. Essencialmente, esse glossário é uma lista de nomes, da linguagem ubíqua do sistema, acompanhados por uma breve explicação. Ele tem dois objetivos:
Evitar que o mesmo conceito seja referenciado por dois ou mais nomes. Por exemplo, em um sistema de comércio eletrônico, queremos evitar que sejam usados nomes como Cliente, Usuário, Comprador, etc., todos sendo sinônimos. Ou seja, a recomendação é padronizar um nome e usá-lo em todo o sistema.
Evitar que conceitos diferentes sejam referenciados pelo mesmo nome. Por exemplo, em um sistema de uma universidade, queremos evitar que o nome curso seja usado para significar uma disciplina (exemplo: Introdução à Programação) e também um curso superior (exemplo: Ciência da Computação). Ou seja, nesse caso, é melhor padronizar e usar dois nomes: disciplina e curso.
Concluindo, a linguagem ubíqua é o vocabulário usado diariamente para comunicação entre desenvolvedores e especialistas no domínio de um sistema. Esse vocabulário deve ser padronizado, consistente e de amplo conhecimento dessas duas partes. Além disso, ele deve ser um vocabulário vivo, pois novos nomes podem ser necessários para lidar com manutenções adaptativas e evolutivas em um sistema.
2.7 Implemente Funções Coesas e Desacopladas 🔗
Uma propriedade fundamental de design de qualquer função é sua
coesão. Isto é, toda função deve fazer uma coisa,
fazer isso bem e fazer apenas isso
, conforme resume Robert C.
Martin, no seu livro Clean Code (página 35). Por isso, coesão
tem impacto direto na legibilidade de uma função. Isto é, se uma função
faz diversas coisas, será claramente mais difícil entender seu
funcionamento.
Por exemplo, suponha que em um sistema de comércio eletrônico existe uma função que faz duas coisas: (1) seleciona o melhor centro de distribuição para entrega de um produto e (2) calcula a remuneração do afiliado responsável pelo link que gerou a compra desse produto. Veja que são requisitos diferentes e que não têm relação entre si. Logo, essa função deveria ser quebrada em duas funções mais coesas e de mais fácil entendimento.
Outro exemplo é uma função cujo código realiza as seguintes tarefas: (1) calcula o valor do frete; (2) exibe esse valor na interface web do sistema; e (3) armazena o valor em cache. Essa função também não é coesa, embora todas as tarefas se relacionem com o frete de produtos. No entanto, a primeira delas é um requisito funcional, ou, como costumamos dizer, uma regra de negócio. A segunda é uma tarefa de apresentação, isto é, de interface com o usuário. Por fim, a terceira corresponde a um requisito não funcional, pois visa a melhorar o desempenho do sistema por meio do uso de um cache.
Outra decisão que gera alguma polêmica diz respeito ao tamanho de uma
função em linhas de código. Existem autores que são enfáticos nesse
ponto, como Robert C. Martin, que afirma o seguinte: A primeira regra
de uma função é que elas devem ser pequenas. A segunda regra é que elas
devem ser menores ainda do que isso
(Clean Code, página
34). Outros autores são mais flexíveis, como John Ousterhout, que afirma
o seguinte:
Eu concordo que funções pequenas são geralmente mais fáceis de entender do que funções grandes. Mas uma questão mais importante é a seguinte: quebrar uma função em funções menores reduz a complexidade global de um sistema? Em outras palavras, é mais fácil ler diversas funções pequenas e entender como elas trabalham em conjunto do que ler uma função grande? (A Philosophy of Software Design, Seção 9.8).
Essa frase de Ousterhout remete a uma outra propriedade de design,
chamada acoplamento. Em termos simples, se uma função
f chama uma função g, dizemos que
f está acoplada (ou depende) de g. Então,
quando um sistema possui muitas funções pequenas, elas não serão
ilhas isoladas
. Pelo contrário, elas vão depender umas das
outras, o que gera acoplamento e prejudica o entendimento do
sistema.
Em resumo, a decisão sobre o tamanho de uma função deve ser bidimensional, isto é, ela deve considerar tanto coesão como acoplamento, tal como o comentário de Ousterhout sugere. Ou seja, aqui também vale a recomendação clássica de design de software: maximize a coesão e minimize o acoplamento, também de funções, e assim elas ficarão mais legíveis.
Code Smells Relacionados com Funções: Somente para lembrar, code smells são construções de código que, a princípio, devem ser evitadas. No caso específico, funções muito grandes, em praticamente qualquer cenário, são consideradas um code smell. O motivo é que, por serem grandes, elas tendem a ser pouco coesas, justamente por possuírem múltiplas responsabilidades.
No entanto, a definição de muito grande
não é puramente
objetiva. Mas arriscamos a dizer que funções com mais de 20 linhas são
candidatas a serem quebradas em funções menores.
Outro code smell conhecido são funções com muitos parâmetros. Essa característica é um alerta de que a interface (ou assinatura) da função é por demais complexa e, portanto, devemos avaliar se alguns de seus parâmetros não podem ser agrupados em um tipo. Para ilustrar, mostraremos um exemplo simples de uma função com muitos parâmetros:
void processarPedido(String cliente, String rua,
String complemento, String cidade,
String estado, String cep) {
...
}
Então, para reduzir o número de parâmetros dessa função, eles podem
ser encapsulados em um tipo Endereco:
void processarPedido(String cliente, Endereco endereco) {
...
}Alguns autores como Joshua Bloch são mais específicos em relação ao número de parâmetros de uma função e recomendam o seguinte:
Procure ter no máximo quatro parâmetros. A maioria dos programadores não consegue lembrar listas de parâmetros mais longas. Se muitos dos seus métodos excederem esse limite, sua API não será utilizável sem consultas frequentes à documentação. (Effective Java, Chapter 8, item 51)
Retornos Antecipados: Outra estratégia que ajuda a
melhorar o entendimento e a leitura de uma função consiste em usar,
quando possível, Retornos Antecipados (Early Returns). A ideia
é a seguinte: em uma função, sempre que você fizer um teste, tente já
tomar uma decisão, em vez de fazer um novo teste. Essa decisão pode ser
inclusive retornar da função, por meio de um return.
Primeiro, vamos mostrar um exemplo que não usa retornos antecipados:
String getConceito(int nota) {
String conceito;
if (nota < 0 || nota > 100) {
conceito = "Nota inválida";
} else if (nota >= 90) {
conceito = "A";
} else if (nota >= 80) {
conceito = "B";
} else if (nota >= 70) {
conceito = "C";
} else if (nota >= 60) {
conceito = "D";
} else {
conceito = "F";
}
return conceito;
}Agora veja uma nova versão usando retornos antecipados:
String getConceito(int nota) {
if (nota < 0 || nota > 100) {
return "Nota inválida";
}
if (nota >= 90) {
return "A";
}
if (nota >= 80) {
return "B";
}
if (nota >= 70) {
return "C";
}
if (nota >= 60) {
return "D";
}
return "F";
}O segundo código é mais limpo e fácil de entender, pois ele usa
apenas comandos if e return, sem necessidade
de nenhum else. Basicamente, cada if já
descobre um determinado conceito e o retorna de imediato.
2.8 Separe o Fluxos de Execução Normal e Excepcional 🔗
Podemos dividir o código de um sistema em duas partes: código que
trata do fluxo normal (ou fluxo feliz
) e código que trata
situações que não são normais (ou exceções). O problema é que o segundo
tipo de código é mais difícil de entender, pois ele trata os casos
especiais. Apesar disso, evidentemente, ele precisa ser escrito, pois
nossos sistemas devem ser robustos, isto é, capazes de lidar com
entradas incorretas ou com situações imprevistas, como falta de memória
ou um erro na gravação de um dado em um arquivo.
Na verdade, tratamento de exceções pode ter mais linhas de código do que o tratamento de casos normais. Isso tende a ocorrer em sistemas críticos, como aqueles que rodam em aviões, foguetes, metrôs, dispositivos médicos, satélites, etc.
Além disso, quando misturamos tratamento de exceções com a implementação dos casos normais, a legibilidade e o entendimento do código ficam comprometidos, como mostra o seguinte exemplo:
boolean ok = abrirArquivo(nomeArquivo);
if (ok) {
int tamanho = obterTamanhoArquivo(nomeArquivo);
if (tamanho != 0) {
byte[] dados = alocarMemoria(tamanho);
if (dados != null) {
lerArquivo(nomeArquivo, dados);
processarDados(dados);
} else {
// exceção: memória insuficiente
}
} else {
// exceção: arquivo vazio
}
} else {
// exceção: arquivo inexistente
}Esse código possui três comandos if antes de chegar ao
processamento do caso normal. Além disso, ele possui três comandos
else para tratar cada caso de erro. Por isso, o código não
é dos mais legíveis, pois o tratamento de erros acaba se misturando e
poluindo a implementação do caso normal.
Para resolver esse problema, várias linguagens oferecem comandos
try-catch para tratamento de exceções. Por exemplo, Java,
C++, C#, Python, JavaScript e PHP. Usando esses comandos, o código
anterior pode ser escrito da seguinte forma:
try { // fluxo normal
abrirArquivo(nomeArquivo);
int tamanho = obterTamanhoArquivo(nomeArquivo);
byte[] dados = alocarMemoria(tamanho);
lerArquivo(nomeArquivo, dados);
processarDados(dados);
}
catch (ExcecaoArquivoInexistente e) {
IO.println("Arquivo não encontrado.");
}
catch (ExcecaoArquivoVazio e) {
IO.println("Arquivo está vazio.");
}
catch (ExcecaoMemoriaInsuficiente e) {
IO.println("Memória insuficiente para carregar arquivo.");
}A vantagem do segundo código é que ele separa, de forma explícita, os
dois fluxos. No bloco try, temos o fluxo normal de
execução, sem qualquer preocupação ou teste para verificar erros. No
entanto, caso um dos comandos do bloco try ative uma
exceção (via um comando throw) a execução é desviada para
um bloco catch capaz de tratá-la. Em outras palavras, um
throw, de um ponto de vista mais prático, funciona como um
goto para um catch.
Assim, ao ler o código anterior, podemos primeiro focar no
entendimento do bloco try (fluxo feliz) e, somente depois,
focar no entendimento dos blocos catch, que são os
tratadores de exceções.
No entanto, temos que lembrar que blocos try-catch não
eliminam o esforço para tratar exceções. Os dois fluxos (normal e
exceções) são separados, mas continuamos tendo que implementar o segundo
fluxo (tratadores de exceção). Na verdade, é comum que os blocos
catch, quando somados, tenham mais linhas de código do que
o bloco try.
2.8.1 Boas Práticas para Tratamento de Exceções 🔗
Vamos agora apresentar três recomendações mais específicas para tratamento de exceções.
1. Use exceções apenas para tratar situações excepcionais. Essa recomendação parte do pressuposto de que exceções são realmente o que o nome significa, isto é, situações anormais e que não conseguimos prever. Consequentemente, não devemos usar exceções para tratar situações que fazem parte do comportamento esperado de uma função ou que não implicam uma mudança de fluxo, isto é, do fluxo feliz para o fluxo excepcional. Vamos dar dois exemplos:
Suponha uma função que retorna os clientes de uma empresa que moram em uma cidade passada como parâmetro. Porém, o fato de nenhum cliente morar em uma determinada cidade não é exatamente uma exceção. Ou seja, em tais casos, a função não deve retornar uma exceção, mas sim um resultado normal, no caso, uma lista vazia.
Suponha uma função que marca uma mensagem em um sistema de chat como lida. No entanto, se a mensagem já possuir essa marcação, o melhor é simplesmente retornar, sem fazer nada. Nesse caso, usar uma exceção apenas para dizer que a mensagem já está marcada como lida é uma complicação desnecessária.
Em resumo, uma exceção deve ser levantada apenas quando sua ocorrência implicar em uma mudança de fluxo: não estamos mais em um caminho feliz no programa, mas em uma situação, de fato, anormal e difícil de prever.
2. Nunca use blocos catch vazios. Nunca devemos
implementar blocos catch como o seguinte:
try {
...
} catch (AlgumaExcecao e) { }Esses blocos apenas silenciam a exceção que acabou de ocorrer. É como se uma casa estivesse pegando fogo e a nossa decisão fosse desligar o alarme e ignorar o incêndio. Portanto, se não conseguimos tratar uma exceção e voltar ao fluxo normal de execução, é melhor optar por uma das seguintes alternativas:
Gerar uma mensagem de log descrevendo a exceção e por que ela não precisa ser tratada.
Não implementar (ou deletar) o
catchvazio e deixar a exceção ser propagada para um blococatchmais externo. Essa alternativa pode levar ao término do programa, como também explicaremos a seguir. Mas, pelo menos, o programa não irá terminar normalmente, mas sim com uma exceção levantada e não tratada. Em outras palavras, nãojogamos a exceção para debaixo do tapete.
3. Just Crash. A ideia desta terceira recomendação é
a seguinte: em muitos casos, a melhor alternativa consiste em não tratar
exceções mais severas e deixar o programa terminar. Um exemplo comum são
exceções que representam erros de programação, como indexação de um
vetor fora dos limites permitidos ou divisão por zero, e exceções
causadas por falta de memória. Em Java, por exemplo, o operador
new levanta uma exceção OutOfMemoryError se
não existir memória disponível para criar um objeto. Por um lado, os
projetistas da linguagem estavam certos ao definir que essa situação
representa uma exceção. Por outro lado, programadores de Java,
normalmente, não devem tratar essa exceção, pois não há muito o que
fazer se o sistema operacional não possui memória para executar o seu
programa. Nesses casos, o melhor é deixar a exceção ser propagada ao
longo da pilha de chamadas de funções, até chegar ao main,
quando o programa será terminado com uma mensagem de erro, indicando que
uma exceção foi levantada mas não se encontrou um catch
para tratá-la.
Literatura Científica: Em um estudo publicado em
2016, pesquisadores da Carnegie Mellon University, nos EUA, analisaram
mais de 11 milhões de blocos try-catch coletados de
projetos de código aberto implementados em Java e disponíveis no GitHub
(link). Eles
chegaram a uma conclusão surpreendente: 12% dos blocos
catch analisados eram vazios, o que conforme comentamos é
uma prática inadequada para tratamento de exceções.
Mundo Real: Tcl é uma linguagem de script projetada
pelo professor John Ousterhout, da Universidade de Stanford. Em seu
livro A Philosophy of Software Design ele comenta sobre o
comando unset dessa linguagem, o qual remove uma variável,
passada como parâmetro, da memória do interpretador. Se a variável não
existir, levanta-se uma exceção. No entanto, segundo Ousterhout, esse
foi um dos maiores erros que ele cometeu no projeto de Tcl. Segundo ele,
o melhor nesse caso teria sido não fazer nada. Para confirmar sua tese,
ele comenta que desenvolvedores frequentemente fazem isso, ou seja, eles
usam blocos catch vazios para lidar com essas exceções.
2.8.2 Erros como Valores 🔗
A maioria das linguagens de programação propõe a divisão dos fluxos
de execução em blocos try e blocos catch,
conforme explicamos antes na seção. Porém, antes de concluir,
gostaríamos de destacar que essa divisão não é consensual.
Especificamente, existem linguagens que adotam uma solução chamada de
Erros como Valores (Errors as Values). Como exemplo, podemos
citar Go, Rust e também linguagens funcionais, como Elixir e Erlang.
Essas linguagens advogam que não existe uma vantagem inequívoca na
separação dos fluxos de execução. Em vez disso, elas propõem que erros
sejam um segundo valor de retorno para uma função. Ou seja, funções
podem retornar valores normais, mas também erros. Para ilustrar,
mostramos uma função de divisão em Python (usando exceções e blocos
try-except):
def dividir(a, b):
if b == 0:
raise ValueError("Divisão por zero")
return a / b
def main():
try:
resultado = dividir(5, 0)
print(f"Resultado: {resultado}")
except ValueError as erro:
print(f"Erro: {erro}")No paradigma de Erros como Valores, essa função seria implementada da seguinte forma:
def dividir(a, b):
if b == 0:
return None, "Divisão por zero"
return a / b, None
def main():
resultado, erro = dividir(5, 0)
if erro:
print(f"Erro: {erro}")
else:
print(f"Resultado: {resultado}")Evitamos mostrar o segundo código em Go ou em uma linguagem
funcional, pois elas possuem uma sintaxe menos conhecida. E também
porque o importante é que o leitor perceba que a função retorna agora
dois valores: o resultado normal e um valor de erro. O valor de erro
pode ser None ou uma string que descreve o erro. Cabe a
quem chama a função, como o main do programa, testar o
valor de erro, o que ocorre no fluxo normal mesmo, por meio de um
if.
No entanto, com essa discussão sobre Erros como Valores não queremos
confundir o leitor. Em vez disso, nosso intuito é apenas mencionar que
tratamento de erros é sempre custoso e requer um número considerável de
linhas de código. Existe uma solução tradicional, implementada por
várias linguagens, que propõe dividir o código em dois fluxos
(try e catch). Porém, essa solução não é uma
bala de prata. Prova disso é que linguagens recentes, como Go e Rust,
optaram por adotar a solução antiga, baseada em retornar erros como
resultado e testar tais retornos por meio de comandos
if.
Bibliografia 🔗
John Ousterhout. A Philosophy of Software Design, Yaknyam Press, 2018.
Robert C. Martin. Clean Code. A Handbook of Agile Software Craftsmanship, Pearson Education, 2009.
Marco Tulio Valente. Engenharia de Software Moderna: Princípios e Práticas para Desenvolvimento de Software com Produtividade. Editora Independente, 2020.
Bertrand Meyer. Object-Oriented Software Construction, Prentice-Hall, 1997.
Eric Evans. Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley, 2003.
Joshua Bloch. Effective Java. Third Edition, Addison-Wesley, 2017.
Exercícios 🔗
1. Quais erros de formatação existem no código da seguinte função?
1: public static void ordenar(int[] vetor){
2: int tam = vetor.length;
3: boolean trocou;
4:
5: for (int i = 0; i < tam - 1; i++) {
6: trocou = false;
7: for (int j = 0; j < tam - i - 1; j++){
8: if (vetor[j] > vetor[j + 1])
9: {
10: int temp = vetor[j];
11: vetor[j] = vetor[j + 1];
12: vetor[j + 1] = temp;
13: trocou= true;
14: }
15: }
16: if (!trocou) break;
17: }
18: }2. O guia de estilo Java que estudamos na Seção 2.2 recomenda que
métodos redefinidos em subclasses devem ser anotados com um
@Override. Justifique essa recomendação. Qual a vantagem
ela traz para leitores de tais métodos?
3. Quando se desenvolve software no Brasil, deve-se usar nomes em português ou inglês? Melhor dizendo, quando se deve adotar nomes em inglês? E quando se deve adotar nomes em português? Observação: esta é uma questão para discussão e não possui uma resposta totalmente objetiva.
4. Qual crítica relacionada com a adoção de uma linguagem ubíqua você faria em relação à implementação das seguintes classes?
public class Registry<E> {
public boolean add(E element) {...}
public E get(int index) {...}
public boolean remove(E element) {...}
}
public class Dictionary<K, V> {
public V put(K key, V value) {...}
public V retrieve(K key) {...}
public V delete(K key) {...}
}5. Qual crítica você faria à implementação da seguinte função?
void processarDocumento(int docID, boolean backup) {
if (backup) {
// código para salvar documento no disco
} else {
// código para imprimir documento
}
}6. Qual crítica você faria ao uso de exceções pela seguinte função?
List<Produto> buscarProdutos(String categoria)
throws ProdutoNaoEncontradoException {
List<Produto> produtos = repositorio.buscar(categoria);
if (produtos.isEmpty()) {
throw new ProdutoNaoEncontradoException(categoria);
}
return produtos;
}7. Qual crítica você faria aos blocos catch do seguinte
código:
try {
... // código para processar matrículas da universidade
}
catch (CursoLotadoException e) {
...
}
catch (PreRequisitoNaoAtendidoException e) {
...
}
catch (MatriculaEncerradaException e) {
...
}8. Qual a crítica relativa a tratamento de exceções você faria em relação ao seguinte código? (baseado em um exemplo do livro Effective Java, de Joshua Bloch, Chapter 10, item 69).
try {
int i = 0;
while (true) {
list[i++].execute();
}
}
catch (ArrayIndexOutOfBoundsException e) {}