
Fundamentos de Manutenção de Software
4 Código Flexível a Mudanças 🔗
In the practical world of computing, it is rather uncommon that a program, once it performs correctly and satisfactorily, remains unchanged forever. ― Niklaus Wirth (Program Development by Stepwise Refinement, 1971)
Este capítulo começa discutindo os tipos de mudanças que podem acontecer em um sistema (Seção 4.1). Em seguida, tratamos da propriedade de projeto conhecida como Ocultamento de Informação (Information Hiding), a qual tem como objetivo fomentar o projeto de módulos que possam ser mantidos sem requerer mudanças em outros módulos (Seção 4.2). Infelizmente, no entanto, nem sempre é possível restringir mudanças ao código interno de um módulo. Ou seja, em alguns casos, as mudanças vão chegar à interface do módulo, sendo chamadas de Breaking Changes (Seção 4.3). Continuando, na Seção 4.4, vamos estudar alguns recursos que linguagens de programação e técnicas de projeto de software oferecem para tornar a implementação de um módulo aberta a extensões e customizações, tais como parâmetros, funções de ordem superior, classes genéricas, interfaces, injeção de dependência e padrões de projeto. O objetivo é permitir que os próprios clientes adaptem a funcionalidade de um módulo, sem precisar modificar a sua implementação. Por fim, na Seção 4.5, tratamos de um antipadrão de projeto, conhecido como overengineering ou complexidade excessiva (e desncessária).
4.1 Introdução 🔗
Já estudamos que código deve ser escrito para otimizar sua leitura
(Capítulo 2). Por isso, é importante também escrever comentários
(Capítulo 3). No entanto, além de legível, código deve ser flexível a
mudanças. O motivo é que sistemas de software podem ser usados por anos.
Porém, eles não permanecem congelados
, tal como implementados na
primeira versão. Durante esses anos, como sugere a frase do Prof. Wirth
que abre este capítulo, eles sofrem constantes mudanças para se adaptar
a novas funcionalidades, clientes, negócios e tecnologias, incluindo
linguagens de programação, bibliotecas e bancos de dados.
Logo, ao escrever código, é importante ter em mente que ele será alterado no futuro e preparar o terreno para facilitar tais mudanças. Para organizar o nosso estudo, vamos dividir as mudanças em sistemas de software em dois grupos:
Mudanças na implementação interna de um módulo. Especificamente, queremos que tais mudanças não afetem os clientes do módulo, conforme iremos discutir na Seção 4.2.
Mudanças na interface de um módulo, as quais devem ser minimizadas, pois vão exigir mudanças nos clientes do módulo. Na literatura de Engenharia de Software, essas mudanças de interface, que
quebram
clientes, são chamadas de Breaking Changes e serão discutidas na Seção 4.3.
Adicionalmente, sempre que for interessante, queremos que os
próprios clientes de um módulo sejam capazes de configurá-lo às suas
necessidades e requisitos. Ou seja, um módulo deve ser aberto a
extensões e customizações, as quais não devem exigir edições em seu
código. Essa característica é tão importante que motivou a proposição de
um princípio de projeto, chamado de Princípio
Aberto/Fechado, o qual constitui a letra O
(Open/Closed)
dos princípios de projeto conhecidos pela sigla SOLID. Na Seção 4.4,
vamos então tratar de técnicas para projeto e implementação de código
aberto a mudanças.
4.2 Ocultamento de Informação 🔗
Ocultamento de Informação (Information Hiding) é uma propriedade de projeto de software, proposta por David Parnas em 1972, em um dos artigos mais clássicos da área de Engenharia de Software (link). Atualmente, não é difícil entender essa propriedade, mas o mérito de Parnas foi enunciá-la quando a Engenharia de Software ainda dava seus primeiros passos, no início da década de 1970.
Quando falamos de Ocultamento de informação, mencionamos sempre o termo módulo. Então, vamos primeiro definir esse termo. Um módulo, na literatura de Engenharia de Software, designa qualquer estrutura de código que possui uma interface e uma implementação, ou seja:
módulo = interface + implementação
A interface é a parte do módulo visível para seus clientes, isto é, ela especifica os serviços (funcionalidades) que o módulo oferece para seus clientes. Já a implementação é o que o próprio nome diz, ou seja, a implementação de tais serviços. A vantagem dessa definição é que ela abrange estruturas de programação mais antigas e também mais novas. Ou seja, são exemplos de módulos estruturas como funções, classes, pacotes, bibliotecas e microsserviços.
Por exemplo, uma função possui uma assinatura (ou cabeçalho) que constitui sua interface e um corpo ou implementação, delimitado, em muitas linguagens, por chaves. Uma classe possui um conjunto de atributos e métodos públicos (interface) e um outro conjunto de atributos e métodos privados (implementação). Já um microsserviço — um conceito que ainda não existia na década de 1970 — possui uma API (que constitui sua interface) e uma implementação.
Uma vez tendo definido o conceito de módulo, vamos agora explicar o conceito de Ocultamento de Informação. A ideia central é a seguinte: todo módulo possui elementos de código que, com grandes chances, vão mudar no futuro. Então, o conceito de Ocultamento de Informação recomenda que esses elementos sujeitos a mudanças não devem fazer parte da interface do módulo, mas apenas da sua implementação.
Veja que nessa definição usamos o termo módulo. Logo, Ocultamento de Informação se aplica a funções, classes, bibliotecas, microsserviços e a qualquer nova estrutura de programação que venha a ser inventada no futuro e que possua interface e implementação. Por esse motivo, Ocultamento de Informação é um dos conceitos fundamentais de Projeto de Software, ou seja, um conceito que é independente de tecnologia e dos avanços futuros em linguagens de programação.
Mas uma pergunta que ainda não respondemos, pelo menos de forma objetiva, é a seguinte: qual é a vantagem de Ocultamento de Informação?
Como o leitor deve estar imaginando, a resposta é que Ocultamento de Informação facilita mudanças na implementação de um módulo. Explicando melhor, ao seguir esse conceito, ganhamos flexibilidade para mudar a implementação de um módulo (sua parte oculta ou privada), pois sabemos que isso não terá impacto nos clientes do módulo, já que eles usam somente a sua interface (parte pública). Por exemplo, podemos renomear funções, trocar algoritmos por outros mais eficientes, remover campos das tabelas de banco de dados, desde que tais estruturas sejam de uso exclusivo da implementação do módulo e, portanto, invisíveis para seus clientes.
Concluindo, a recomendação principal de Ocultamento de Informação é a
seguinte: quando for implementar um módulo, seja ele uma função, classe,
biblioteca ou microsserviço, pense bem e projete com calma sua parte
visível (interface), pois ela será usada pelos seus clientes. De forma
complementar, oculte todas as informações que os clientes não precisam
saber. Agindo assim, você estará comprando
o direito de amanhã
mudar a implementação do seu módulo sem causar impacto nos clientes do
mesmo.
Exemplo 1: Uma violação de Ocultamento de Informação ocorre quando uma classe declara como público um membro que, claramente, deveria ser privado. Por exemplo, seja a seguinte classe:
class CarrinhoDeCompras {
...
public List<Item> itens; // viola ocultamento informação
...
public CarrinhoDeCompras() {
itens = new ArrayList<>();
...
}
public static void main(String[] args) {
CarrinhoDeCompras carrinho = new CarrinhoDeCompras();
carrinho.itens.add(new Item("Teclado", 120.0));
carrinho.itens.add(new Item("Mouse", 50.0));
...
}
}Essa classe expõe publicamente uma estrutura de dados essencial: a
lista de itens de um carrinho de compras. Depois, essa lista é usada no
método main para adicionar dois produtos em um determinado
carrinho.
Portanto, para facilitar mudanças futuras em
CarrinhoDeCompras, a lista de itens deve ser privada e deve
ser criado um método público chamado adicionarItens. Dessa
forma, o desenvolvedor da classe fica livre para mudar a estrutura de
dados que armazena os itens comprados, sem afetar qualquer código que
usa a classe. Por exemplo, futuramente, ele pode querer armazenar os
itens em uma estrutura de dados mais eficiente que venha a ser
disponibilizada pela biblioteca padrão da linguagem de programação.
Exemplo 2: O seguinte código também viola Ocultamento de Informação. Ele retorna os dados de um livro com base no seu ISBN (que é um identificador universal de livros).
import java.sql.ResultSet;
import java.sql.SQLException;
public class LibraryServices {
public ResultSet getBookByISBN(String isbn)
throws SQLException {
...
}
}O problema aqui é que a assinatura (ou interface) de
getBookByISBN deixa escapar dois tipos internos da
implementação do método: ResultSet e
SQLException. Assim, os desenvolvedores perdem a
flexibilidade de mudar a tecnologia de acesso a dados, pois a interface
do método menciona que ele usa um banco de dados relacional.
Consequentemente, os clientes que chamam o método ficarão acoplados aos
tipos ResultSet e SQLException e vão, com
certeza, reclamar se mudarmos para um banco de dados que use tipos com
nomes diferentes.
Uma solução seria usar a seguinte assinatura em
getBookByISBN:
public class LibraryServices {
public Book getBookByISBN(String isbn)
throws BookRetrievalException {
...
}
}
Basicamente, trocamos classes específicas de uma tecnologia de banco
de dados por classes do domínio do sistema. O método não retorna mais um
ResultSet, mas uma instância de uma classe de domínio
chamada Book. Além disso, ele não retorna uma exceção
acoplada a um banco de dados, como SQLException, mas uma
exceção também relacionada com o domínio do sistema, isto é,
BookRetrievalException.
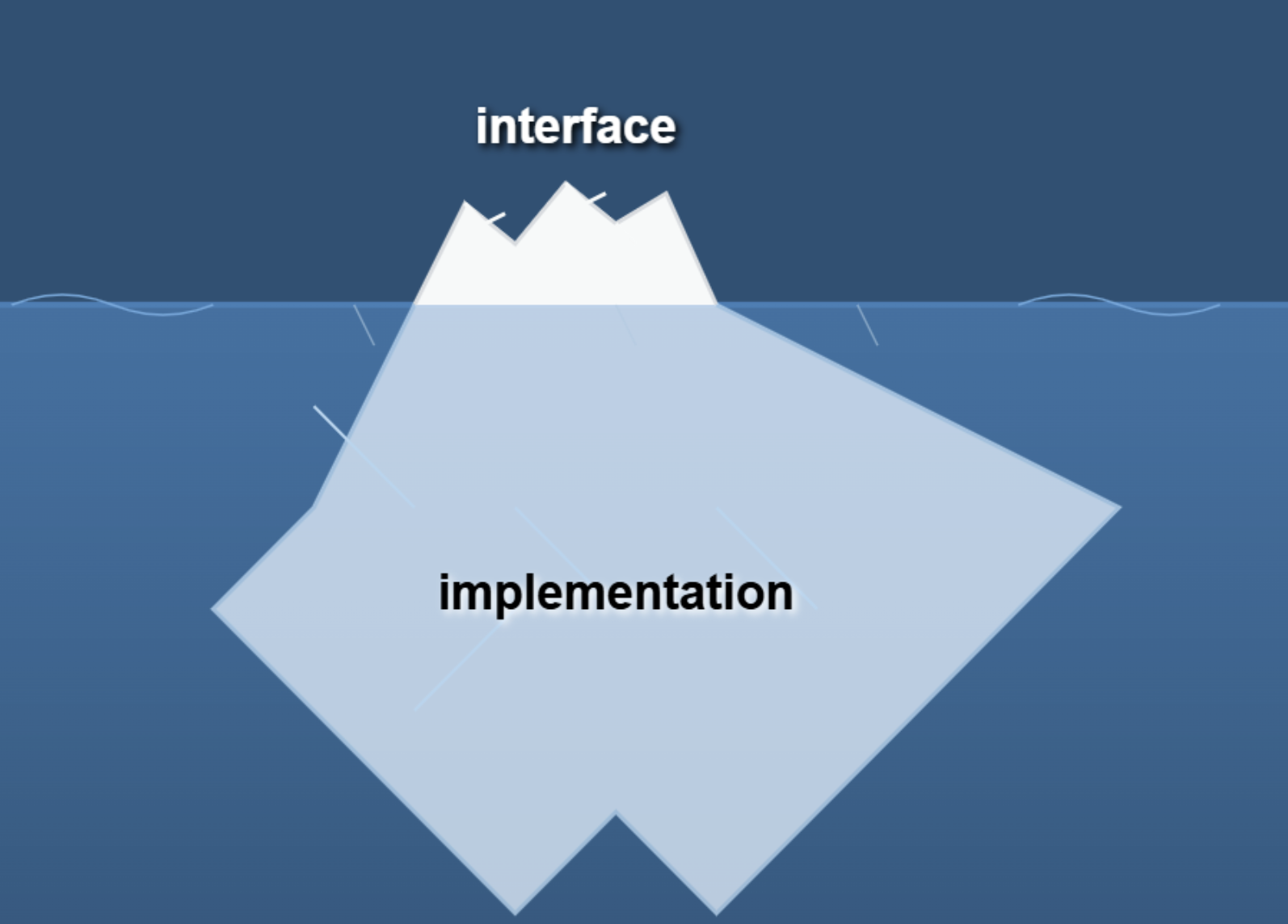
Exemplo 3: Em um livro da década de 1980 (link), o Prof. Bertrand Meyer usou uma metáfora interessante para explicar o conceito de Ocultamento de Informação. Segundo Meyer, módulos devem ser como icebergs, como ilustrado na próxima figura, isto é, devem ter uma pequena ponta, que constitui a interface do módulo, mas também devem ter uma grande base, que constitui sua implementação. Tal implementação fica submersa e, portanto, não é visível aos clientes do módulo. Essa metáfora ajuda a descrever uma segunda propriedade importante em módulos: a interface deve ser bem menor do que a implementação. Ou seja, módulos devem ocultar muito código (ou complexidade) por trás de uma interface pequena, simples e fácil de usar.
Perguntas Frequentes
Qual é a diferença entre os termos Ocultamento de Informação e Encapsulamento? Eles são sinônimos. Por exemplo, o livro Object-Oriented Software Construction, de Bertrand Meyer, inclui um glossário sobre orientação a objetos (link). Nele, a entrada destinada a encapsulamento simplesmente redireciona o leitor para a entrada sobre Ocultamento de Informação.
O que significa o termo Vazamento de Informação (Information Leakage)? Alguns autores, como John Ousterhout, usam este termo para designar a falta de Ocultamento de Informação. Ou seja, o contrário de Information hiding é denominado Information leakage.
Qual a diferença entre os termos interface e API? Eles são parecidos e, frequentemente, usados indistintamente. Mas, dito isso, preferimos usar o termo interface de forma genérica, como sendo um conjunto de assinaturas de elementos públicos, isto é, que podem ser usados por terceiros. Por outro lado, usamos o termo API (Application Programming Interface) para designar a interface de uma aplicação independente e importante. Como exemplo, usamos APIs para denominar as interfaces de sistemas como Google Maps, GitHub, Android, um sistema de pagamentos (como o PIX), o backend de um sistema de informação, etc. Portanto, nessa nossa definição, toda API é uma interface, mas nem toda interface merece ser chamada de API.
4.3 Breaking Changes 🔗
As interfaces de um módulo devem também ser estáveis. O motivo é que mudanças na interface demandam atualizações nos clientes do módulo. Por outro lado, os requisitos de um sistema mudam com frequência e muitas vezes essas mudanças acabam atingindo não só a implementação, mas também a interface de um módulo.
Portanto, devemos projetar módulos que ocultem as partes do código sujeitas a mudanças, como discutido na seção anterior. Porém, é preciso reconhecer que algumas mudanças serão mais profundas e vão exigir alterações nas interfaces. Tais modificações são chamadas de breaking changes, justamente porque quebram os clientes do módulo, isto é, obrigam esses clientes a realizar adaptações para usar a nova interface.
Suponha uma interface com uma função chamada f. São
exemplos de breaking changes:
- Renomear
f - Adicionar ou remover parâmetros em
f - Alterar o tipo de retorno de
f
Após as mudanças acima, todo e qualquer código que chama
f deverá ser atualizado para usar a nova assinatura da
função.
Para dar um exemplo mais real, suponha um sistema de comércio eletrônico com o seguinte método:
public void processarPagamento(double valor) { ... }
Suponha que a empresa passou a atender outros países e, portanto, agora é necessário informar a moeda dos preços dos produtos comercializados. Por isso, precisamos alterar a assinatura do método para incluir um parâmetro representando a moeda do pagamento:
public void processarPagamento(double valor, Moeda moeda) {
...
} Essa mudança é uma breaking change porque todas as chamadas do método precisam ser atualizadas para incluir o novo parâmetro. Caso isso não seja feito, ocorrerá um erro de compilação (em linguagens estaticamente tipadas, como Java) ou algum erro em tempo de execução (em linguagens dinamicamente tipadas, como JavaScript e Python).
Literatura Científica: Nosso grupo de pesquisa já realizou alguns estudos para entender o impacto de breaking changes. Por exemplo, um estudo liderado por Aline Brito e colegas monitorou as atividades de manutenção realizadas em 400 sistemas Java, durante quase quatro meses (link). Durante esse período, 61 projetos realizaram mudanças que são breaking changes. No total, detectamos 282 breaking changes, isto é, alguns projetos passaram por múltiplas breaking changes. Portanto, tais resultados mostram que breaking changes são relativamente comuns em projetos de software. Como afirmamos, o motivo é que existe uma necessidade constante de evolução em software, para incluir novos requisitos ou usar novas tecnologias. Essa pressão acaba resultando na introdução de breaking changes.
4.3.1 Tipos de Breaking Changes 🔗
O tipo de breaking change que comentamos acima é chamado de breaking change sintática, porque a mudança ocorreu na assinatura dos métodos de uma interface. Porém, existe um segundo tipo, chamado de breaking change comportamental. Ele designa mudanças no comportamento dos métodos de uma interface que não implicam em mudanças de assinatura. Como exemplo, suponha uma interface com um método para calcular a distância entre duas cidades. Antes, os resultados eram retornados em milhas, mas uma mudança de requisitos demandou que os resultados passassem a ser retornados em quilômetros. Ou seja, a assinatura do método foi preservada, mas a sua lógica foi modificada. Breaking changes comportamentais não são detectadas por compiladores ou interpretadores, mas por meio de testes automatizados, normalmente por testes de unidade.
A seguir vamos comentar sobre práticas para atenuar ou documentar os efeitos de breaking changes, incluindo depreciação, uso de versionamento semântico, release notes e versionamento de interfaces.
4.3.2 Depreciação 🔗
Depreciação é uma sinalização de que um método não deve ser usado,
pois ele será removido em versões futuras de um sistema. Suponha o
exemplo do método processarPagamento. Nesse caso,
poderíamos optar por manter o método com apenas um parâmetro no código,
mas depreciado. Para isso, bastaria adicionar uma anotação
@Deprecated antes do seu cabeçalho, conforme mostrado a
seguir.
@Deprecated
public void processarPagamento(double valor) {
processarPagamento(valor, Moeda.REAL);
}
public void processarPagamento(double valor, Moeda moeda) {
...
}Como também pode ser observado nesse código, vamos ter duas
implementações de processarPagamento: a versão com apenas
um parâmetro (depreciada) e a nova versão (com dois parâmetros). A
versão depreciada apenas chama o método novo, usando uma moeda padrão
(no exemplo, Real).
A vantagem é que os clientes não precisam se adaptar de forma imediata e podem continuar usando a versão antiga do método. No entanto, o compilador normalmente emite um warning quando encontra uma chamada de um método depreciado, conforme abaixo:
Main.java:24: warning: [deprecation] processarPagamento(double) in
PagamentoService has been deprecated
Uma desvantagem dessa solução é que depreciação, principalmente se usada com frequência e sem critérios, torna a interface de um módulo mais complicada e extensa. Além disso, como o código vai continuar funcionando, os clientes podem adiar a mudança e somente realizá-la quando a versão depreciada for, de fato, removida do código.
Mundo Real: A biblioteca padrão de Java possui casos
interessantes de depreciação. Por exemplo, diversos métodos da classe
java.util.Date foram depreciados em 1997 (Java 1.1), devido
a problemas de projeto. A classe em si, no entanto, nunca foi removida
da linguagem, provavelmente porque existem diversos sistemas escritos
nos anos 1990 que ainda usam essa classe. Em 2022, em um fórum da
comunidade Java, Brian Goetz, um dos principais projetistas da
linguagem, mencionou inclusive que outras classes da biblioteca padrão
esperam ou retornam parâmetros do tipo Date, o que agrava o
problema, pois elas também teriam que ser atualizadas. Evidentemente,
isso aumentaria o número de aplicações clientes impactadas pela mudança.
Um outro exemplo interessante é a depreciação do pacote
java.applet, tecnologia inicialmente proposta por Java para
a execução de código em navegadores Web (antes que JavaScript se
tornasse popular). O pacote já fazia parte da versão 1.0 da linguagem,
lançada em 1996. Ele foi depreciado em 2017, com o lançamento do JDK 9,
e somente completamente removido em 2026, no JDK 26. Ou seja, o processo
de depreciação levou cerca de 10 anos.
4.3.3 Versionamento Semântico 🔗
Releases são as versões de um sistema liberadas para o público externo. Por isso, elas devem ser numeradas, para facilitar a sua identificação. Um padrão comum para essa numeração é chamado de versionamento semântico. Esse padrão propõe que releases sejam numeradas no formato x.y.z, sendo que x, y e z são números inteiros. Esses números são incrementados da seguinte forma:
O valor z é incrementado quando liberamos uma nova release com apenas correções de bugs, as quais são chamadas de patches. Por exemplo, suponha que a última release de um sistema tem o número 3.4.5. Suponha ainda que corrigimos alguns bugs e pretendemos lançar uma nova release. Logo, se usamos versionamento semântico, ela deve ser chamada de 3.4.6.
O valor y é incrementado quando liberamos uma release com novas funcionalidades e, possivelmente, correções de bugs. Porém, essas releases, chamadas de minor releases, não possuem breaking changes. O incremento de y é uma sinalização para os clientes: eles podem migrar para a nova release sem realizar nenhuma mudança no seu código. Por exemplo, suponha que no sistema anterior implementamos algumas funcionalidades, sem breaking changes, e queremos lançar uma nova release. Ela deve ser chamada de 3.5.0 (veja que além de incrementar y também zeramos o valor de z).
O valor x é incrementado quando liberamos uma release com novas funcionalidades que incluem breaking changes (e, possivelmente, também introduzem outras funcionalidades sem breaking changes e correções de bugs). Por isso, elas são chamadas de major releases. Ao incrementar x estamos dando um aviso para os clientes: ao migrarem para essa release, eles terão que realizar mudanças para acomodar as breaking changes. Por exemplo, suponha que no nosso sistema implementamos funcionalidades que implicaram em breaking changes e queremos lançar uma nova release com elas. Ela deve ser chamada de 4.0.0 (veja que além de incrementar x também zeramos y e z).
Com base nessa explicação, é comum ver o formato de numeração proposto por versionamento semântico ser representado da forma: major.minor.patch.
4.3.4 Release Notes 🔗
Quando se lança uma release, deve-se criar um documento, chamado de release notes, que explica de forma resumida todas as mudanças que a release introduz, incluindo correções de bugs, novas funcionalidades e, também, as breaking changes, se for o caso. Esse documento serve para que um cliente, antes de migrar para essa release, conheça as novidades que ela oferece e, também, consiga estimar o esforço que será necessário na migração.
Exemplo: A release notes da versão 19.0.0 da biblioteca React possui seções chamadas New Features, Deprecations e Breaking Changes. Nessa última seção, documentam-se mudanças como as seguintes.
Removed: propTypes: Using propTypes will now be silently ignored. If required, we recommend migrating to TypeScript or another type-checking solution.
Removed: contextTypes and getChildContext: Legacy Context for class components has been removed in favor of the contextType API.
Essas mudanças referem-se a elementos que foram removidos da API do React. Logo, elas são mesmo breaking changes. Veja que elas são documentadas de forma breve, em duas linhas apenas. Também são sugeridas maneiras de contornar a mudança (exemplo: we recommend migrating to TypeScript or another type-checking solution).
4.3.5 Versionamento de APIs 🔗
No caso de APIs Web, costuma-se usar os endpoints da API para indicar a sua versão. Por isso, essa estratégia de versionamento é chamada de versionamento baseado em path. Por exemplo, suponha uma API de um sistema de comércio eletrônico com os seguintes endpoints:
POST v1/produtos
GET v1/produtos
GET v1/produtos/{id}
PUT v1/produtos/{id}
DELETE v1/produtos/{id}
Veja que o próprio caminho do endpoint indica que estamos usando a versão v1 da API. Logo, se a API evoluir de forma a incluir breaking changes, devemos gerar uma nova release da mesma trocando o caminho v1 por v2, por exemplo.
Uma desvantagem dessa forma de versionamento é que ela requer a geração de um conjunto completo de endpoints, mesmo que a breaking change fique restrita a endpoints específicos da API. Por exemplo, suponha que renomeamos alguns campos do JSON com os dados de produto. Essa renomeação é uma breaking change, pois ela requer mudanças nos clientes que acessam os endpoints mostrados acima e que extraem dados dos documentos JSON retornados pela API. Porém, a API do sistema possui outros endpoints, para lidar com usuários, pedidos, entregas, etc. Apesar de não serem afetados pela referida breaking change, esses endpoints deverão ser modificados, para também referenciarem a versão v2 da API.
4.4 Código Aberto a Customizações 🔗
Como afirmado na introdução do capítulo, é importante ter liberdade
para mudar a implementação de um módulo, sem afetar seus clientes. Para
isso, devemos tornar privados os elementos de código com chances de
mudanças no futuro. Em seguida, comentamos que infelizmente algumas
mudanças vão se propagar para as interfaces de um módulo e, portanto,
vão quebrar
os seus clientes. Por isso, devemos documentar essas
mudanças e usar formatos de numeração de releases padronizados, como
versionamento semântico.
Porém, existe uma terceira coisa que podemos fazer para facilitar mudanças em um módulo: torná-lo aberto a extensões e customizações, isto é, implementar o módulo de forma que seus clientes possam mudar alguns aspectos de seu comportamento. Porém, essas mudanças devem ocorrer sem editar o código do módulo, isto é, o seu código deve estar fechado para modificações. Esse princípio de projeto, que advoga a importância de projetar código aberto a customizações, é chamado de Princípio Aberto/Fechado.
Para seguir o Princípio Aberto/Fechado, diversos recursos de linguagens de programação e de projeto de software podem ser usados, incluindo parâmetros, funções de ordem superior, tipos genéricos, interfaces, injeção de dependências e padrões de projeto. Iremos descrever cada um deles nas próximas subseções.
4.4.1 Parâmetros 🔗
Vamos começar com um exemplo simples:
void logMessage() {
IO.println("Alguma coisa deu errado");
}
Esse método imprime sempre a mesma mensagem. Então seria melhor antecipar-se às necessidades dos seus clientes e permitir que eles escolham a mensagem a ser impressa, por meio de um parâmetro, como a seguir:
void logMessage(String msg) {
IO.println(msg);
}Portanto, essa segunda implementação permite que os clientes mudem o comportamento do método, por meio de um parâmetro. Assim, ele vai imprimir uma string definida pelos seus clientes e não mais pelos seus desenvolvedores. Ou seja, o método está aberto a imprimir qualquer mensagem de log, sem que seja preciso mudar a sua implementação.
4.4.2 Funções de Ordem Superior 🔗
Funções de ordem superior são funções (ou métodos) que recebem outras funções como parâmetro (ou que retornam outras funções). Por exemplo, a seguinte função ordena uma lista de inteiros, mas sempre em ordem crescente.
void sort(int[] arr) {
...
}
Logo, os desenvolvedores que chamam essa função — isto é, os clientes
da função — não podem mudar o critério de ordenação. Já a próxima função
é mais flexível, pois possui um segundo parâmetro, do tipo
IntComparator, que recebe uma função responsável pelo
critério de ordenação a ser usado:
void sort(int[] array, IntComparator comparator) {
...
}Logo, nessa segunda implementação, os clientes podem definir o
comportamento de sort, isto é, definir se a ordenação será
ascendente ou descendente, como mostrado a seguir.
int[] vetor = {64, 25, 12, 22, 11};
...
sort(vetor, (a, b) -> a < b); // ordem ascendente
...
sort(vetor, (a, b) -> a > b); // ordem descendente
Ou seja, partimos de uma implementação com um comportamento fixo
(ordenação em ordem ascendente) e flexibilizamos esse comportamento por
meio de uma função de ordem superior. Na segunda implementação, os
clientes podem definir o critério de ordenação que desejam. Para isso,
basta passar uma função simples como parâmetro, a qual determina a ordem
relativa de dois elementos a e b na lista
final. Ela deve retornar true se a deve vir
antes de b e false caso contrário.
Resumindo, a motivação para usar a segunda implementação foi a
seguinte: concluímos que alguns clientes vão precisar de outros
critérios de ordenação, que não sejam apenas em ordem ascendente. Então,
já nos antecipamos e implementamos uma versão de sort para
atendê-los. E o recurso de programação que usamos foi transformar
sort em uma função de ordem superior, isto é, uma função
que possui um parâmetro que também é uma função.
4.4.3 Classes Genéricas 🔗
A seguir mostramos a implementação de uma classe Stack.
Como pode ser observado, ela é muito rígida, pois lida apenas com
inteiros.
class Stack {
private int[] elements; // pilha apenas de inteiros
...
public Stack() { ... } // construtora
public void push(int item) { ... }
...
}
No entanto, se for importante empilhar valores de outros tipos, além
de números inteiros, podemos tornar a classe Stack
genérica, como mostrado neste próximo código:
class Stack<T> {
private List<T> elements;
...
public Stack() { ... }
public void push(T item) { ... }
...
}Nessa nova implementação, a classe possui um parâmetro de tipo
T, que representa o tipo dos elementos armazenados na
pilha. Assim, a mesma implementação pode ser usada para criar pilhas de
diferentes tipos, como Stack<Integer>,
Stack<Double> ou Stack<String>. Em
outras palavras, a pilha deixa de estar limitada a inteiros e passa a
ser parametrizada pelo tipo dos seus elementos.
Por exemplo, se precisarmos de uma pilha para armazenar números reais, podemos usar o seguinte código:
Stack<Double> pilhaReais = new Stack<>();
pilhaReais.push(10.0);
pilhaReais.push(20.0);
pilhaReais.push(30.0);4.4.4 Interfaces, Inversão e Injeção de Dependências 🔗
Para ilustrar esses conceitos, vamos usar uma classe
ControleRemoto:
class ControleRemoto {
TVSamsung tv = new TVSamsung();
...
}
Para ajudar, veja também o diagrama de classes desse código acima:

O leitor já deve ter percebido que a classe
ControleRemoto não é flexível a customizações.
Especificamente, ela controla TVs de um único fabricante. E se amanhã
for preciso controlar TVs de outros fabricantes?
Para resolver essa dependência entre classes, existe o conceito de interface:
interface TVGenerica {
...
}
class TVSamsung implements TVGenerica { ... }
class TVSony implements TVGenerica { ... }
class ControleRemoto {
TVGenerica tv;
...
}
Essa nova implementação pode ser representada pelo seguinte diagrama:

Nesse diagrama, fica claro que ControleRemoto depende de
uma interface, chamada TVGenerica, que apenas declara a
assinatura dos métodos que toda TV deve possuir. Em seguida, temos duas
classes concretas, que implementam essa interface, isto é, implementam
os seus métodos. Então, ControleRemoto não depende mais de
uma classe concreta, mas sim de uma interface.
O princípio de projeto que recomenda colocar uma interface no meio
de duas classes é chamado de Princípio da Inversão de
Dependências, ou DIP, na sigla em inglês. Portanto, ele
corresponde à letra D
dos princípios SOLID. Como esse nome é um
pouco complicado, preferimos chamá-lo de Prefira Interfaces a
Classes Concretas.
O leitor atento deve estar se perguntando também: em qual parte do
programa será criada a classe concreta que o controle remoto vai
acessar? A resposta, mais genérica, é que isso vai acontecer fora da
classe ControleRemoto, por exemplo, no programa
principal.
void main() {
ControleRemoto cr1 = new ControleRemoto(new TVSamsung());
ControleRemoto cr2 = new ControleRemoto(new TVSony());
...
}Portanto, a classe ControleRemoto, na sua construtora,
recebe a instância da TV que será controlada. Esse padrão de projeto,
por meio do qual uma classe recebe suas dependências via parâmetros de
sua construtora, é chamado de Injeção de Dependências.
Em resumo: de novo, temos uma solução que se vale de um parâmetro, no
caso, uma dependência para objetos externos à classe, para criar um
código customizável. Facilmente, podemos ter um controle remoto que
controla TVs da Samsung e um segundo, que controla TVs da Sony.
Concluindo, explicamos, em uma única seção, um conceito muito importante de orientação a objetos (interfaces), um princípio de projeto (Inversão de Dependências, que corresponde à última letra do SOLID) e um padrão de projeto (Injeção de Dependências).
4.4.5 Padrões de Projeto 🔗
Além de Injeção de Dependências, outros padrões de projeto ajudam na implementação de código customizável. A seguir vamos comentar sobre alguns deles.
Uma Fábrica permite trocar os objetos usados por uma aplicação. Por exemplo, suponha um sistema distribuído que usa canais de comunicação baseados em TCP. Se a criação desses canais estiver centralizada em uma Fábrica, fica mais fácil criar uma versão do sistema que usa UDP, em vez de TCP, por exemplo.
Já um Decorador permite adicionar novas
funcionalidades em um objeto base. No exemplo anterior, podemos decidir
que é importante decorar
os canais de comunicação com buffers,
logs, compactadores de dados, etc. Consequentemente, vamos ter uma
funcionalidade básica (comunicação via TCP ou UDP) e várias
funcionalidades opcionais. Os desenvolvedores que usam canais de
comunicação podem habilitar ou desabilitar as funcionalidades opcionais,
de forma parecida como selecionamos opcionais para um carro novo ou como
montamos um sanduíche em uma lanchonete.
Um outro padrão sempre mencionado é o padrão
Estratégia (Strategy), que permite trocar os
algoritmos usados por uma classe. Suponha uma classe Lista
com um método que ordena os seus elementos. Nesse caso, o padrão de
projeto Estratégia pode ser usado para trocar o algoritmo de ordenação.
Por exemplo, a implementação default usa o algoritmo QuickSort. Porém,
se for necessário, os desenvolvedores que usam a lista podem
configurá-la para usar um outro algoritmo de ordenação. Basicamente, o
padrão Estratégia permite que eles pluguem esse novo algoritmo no lugar
do algoritmo default. Assim, sem editar o código da Lista,
podemos mudar um algoritmo usado internamente pela sua
implementação.
Para dar um quarto e último exemplo, um Visitante
(Visitor) permite realizar operações em cada um dos objetos de
uma estrutura de dados polimórfica, isto é, uma estrutura de dados cujos
objetos possuem tipos (ou classes) diferentes. Por exemplo, suponha
agora uma lista usada para armazenar alunos de uma universidade. E que
existam alunos de diferentes tipos: AlunoGraduacao,
AlunoMestrado, AlunoDoutorado, etc. Todos eles
são subclasses de uma classe chamada Aluno. Se a
implementação dessas classes seguir o padrão Visitante, os
desenvolvedores podem escrever um código para visitar — isto é, para
realizar uma operação — em cada aluno armazenado na lista. Essa operação
pode ser a inserção dos dados dos alunos em um banco de dados, a
impressão desses mesmos dados na saída padrão do sistema ou o envio de
uma mensagem para cada aluno, por exemplo. O importante é que os
desenvolvedores de Aluno e de suas subclasses se
anteciparam e tornaram as classes abertas a visitas por parte de código
que será escrito, no futuro, por terceiros.
Uma descrição mais detalhada sobre padrões de projeto pode ser encontrada no nosso livro anterior (Engenharia de Software Moderna, link).
4.5 Complexidade Excessiva (Overengineering) 🔗
Quando se trata de código extensível e customizável, sempre é
importante falar de um antipadrão de projeto, conhecido como
overengineering ou complexidade
excessiva. Ele ocorre quando um desenvolvedor complica sua
implementação, sem que exista necessidade. Popularmente falando, o
desenvolvedor implementa um canhão para matar algumas
formigas
.
Conforme tratamos neste capítulo, muitas vezes é importante investir na implementação de um código customizável. Esse investimento pode se pagar, ao longo do tempo, pois terceiros vão reusar a sua implementação em um contexto diferente daquele que você pensou inicialmente. Logo, em tais casos, vale a pena usar as técnicas que mencionamos neste capítulo.
Por outro lado, em certos casos, a necessidade de adaptação, customização e extensão do código nunca vai existir. Logo, o investimento em implementações mais complexas e abertas não será interessante e não vai se pagar. Se mesmo assim você complicar o código para torná-lo flexível a mudanças, você estará cometendo o erro de projeto que chamamos de overengineering.
Por exemplo, anteriormente, criticamos o código a seguir, porque ele está acoplado para sempre com uma TV da marca Samsung:
class ControleRemoto {
TVSamsung tv = new TVSamsung();
...
}
Porém, pode ser que no seu contexto, isso não seja um problema. Ou seja: você e sua empresa nunca vão usar uma TV de um fabricante diferente. Há décadas sempre usaram Samsung e, em um futuro próximo, não vislumbram motivos para mudar. Logo, tornar o código aberto para controlar outras TVs, por meio da criação de uma interface e do uso de Injeção de Dependências, será uma complicação desnecessária, que vai demandar tempo e não vai trazer retorno.
Bibliografia 🔗
Marco Tulio Valente. Engenharia de Software Moderna: Princípios e Práticas para Desenvolvimento de Software com Produtividade. Editora Independente, 2020.
Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1995.
Robert C. Martin. Clean Architecture: A Craftsman’s Guide to Software Structure and Design, Prentice Hall, 2017.
John Ousterhout. A Philosophy of Software Design, Yaknyam Press, 2nd edition, 2021.
Exercícios 🔗
1. Microsserviços são um padrão arquitetural muito usado. No nome
desse padrão, o termo micro
designa um módulo pequeno
desenvolvido e mantido por um time também pequeno. Já o termo
serviço
lembra que microsserviços rodam como processos
independentes do sistema operacional. Ou seja, cada microsserviço é um
processo separado. Quando comparados com monolitos, por que
microsserviços favorecem um projeto que propicia ocultamento de
informação e que, portanto, permite que mudanças internas ocorram de
modo mais fácil e com menos riscos?
2. (a) Dê um exemplo de uma breaking change sintática; (b) Dê um exemplo de uma breaking change comportamental.
3. O npm (Node Package Manager) é um gerenciador de pacotes usado em
projetos JavaScript para instalar e gerenciar bibliotecas externas. Em
projetos que usam npm, as dependências de um sistema e suas versões são
declaradas em um arquivo chamado package.json. Considere
então o seguinte trecho desse arquivo:
"dependencies": {
"express": "4.18.2",
"moment": "~2.29.4",
"lodash": "^4.17.21"
}Pesquise e explique o significado de cada uma das três formas de
especificação de versão usadas no exemplo (4.18.2
, ~2.29.4
e ^4.17.21
). Quais versões de cada biblioteca podem ser
instaladas segundo definido nesse arquivo?
4. Explique com suas palavras o que significa Injeção de Dependência e quando esse padrão de projeto deve ser usado (isto é, qual o benefício que ele proporciona).
5. O Eclipse é uma IDE para Java, que foi bastante popular, pelo
menos durante um tempo. Ela permite também construir plugins ou
extensões para a IDE, por exemplo, para rodar linters ou mesmo gerar
modelos visuais do código. Para tanto, esses plugins podem chamar
métodos de classes públicas do Eclipse (por exemplo, para acessar o
editor de código, inserir itens em menus e barras de ferramentas, ou
observar eventos de compilação). Ao analisar os pacotes do Eclipse,
podemos observar que vários possuem o nome internal, como
em org.eclipse.jdt.internal.core. (a) O que esse nome
sinaliza para os desenvolvedores de plugins? (b) Por que esses pacotes
foram rotulados como internal?
6. Diversas linguagens de programação possuem o que se chama de frameworks de injeção de dependência. Por exemplo, podemos mencionar Spring e Google Guice para Java. Pesquise sobre os serviços oferecidos por esses frameworks. Qual a vantagem que eles oferecem em relação a injeção de dependências via construtoras de uma classe tal como estudamos neste capítulo?