
Fundamentos de Manutenção de Software
5 Bugs 🔗
There are two ways to write error-free programs; only the third one works. ― Alan J. Perlis (Epigrams on Programming, 1982)
Este capítulo começa definindo o conceito de bugs e de termos relacionados, como defeitos, faltas, falhas e crashes (Seção 5.1). Em seguida, apresentamos os principais tipos de bugs, tais como bugs de memória, de concorrência, de segurança e de entendimento de requisitos (Seção 5.2). A ideia é apresentar um panorama dos tipos mais comuns e relevantes de bugs. Na sequência, tratamos de ferramentas para detecção de bugs, tais como ferramentas de análise estática e ferramentas para identificação de dependências vulneráveis (Seção 5.3). Apesar de não serem perfeitas, essas ferramentas ajudam desenvolvedores a detectar bugs de forma antecipada. Então, passamos a comentar sobre um segundo tipo de ferramenta: os sistemas para rastreamento de bugs (Seção 5.4). Esses sistemas funcionam como o banco de dados de bugs de um projeto, incluindo tanto bugs que ainda estão abertos quanto aqueles que já foram fechados. Uma vez que o sistema de rastreamento de bugs está funcionando, podemos começar a corrigir os bugs. Para isso, no entanto, normalmente seguimos um fluxo de trabalho padronizado, também chamado de ciclo de vida de bugs (Seção 5.5).
5.1 Introdução 🔗
Mesmo que um código seja legível (Capítulo 2), bem documentado (Capítulo 3) e flexível a mudanças (Capítulo 4), em algum momento ele vai apresentar bugs. Por exemplo, se você entrar no repositório GitHub de qualquer sistema conhecido, vai encontrar uma lista de bugs abertos e também de bugs que já foram corrigidos. Para citar um exemplo, no momento da escrita deste capítulo, o repositório do nodejs, um conhecido ambiente para execução de sistemas JavaScript, listava 979 bugs corrigidos e outros 83 bugs abertos. Ou seja, por um lado, é muito importante usar todas as boas práticas de Engenharia de Software para evitar bugs. Por outro lado, realisticamente, temos que admitir que bugs vão existir em todos os sistemas, como sugere o epigrama do Prof. Alan J. Perlis, que abre este capítulo.
No entanto, bug é um termo relativamente informal, sendo defeito o termo mais técnico, por assim dizer. Dizemos que um programa possui um defeito quando ele não está implementado de acordo com sua especificação. Existe ainda o termo falta (do inglês fault) que, segundo o IEEE Standard Glossary of Software Engineering Terminology (link), é um sinônimo de bug. Portanto, esses três termos (bug, defeito e falta) podem ser considerados sinônimos. Por isso, e para simplificar, neste livro, vamos preferir o termo bug, pois ele é também amplamente usado por profissionais da nossa área.
Em relação às suas consequências, bugs podem fazer com que um programa não produza os resultados esperados, isto é, que ele não atenda aos seus requisitos funcionais. Por exemplo, um bug pode fazer com que uma calculadora mostre resultados errados ao somar dois valores. Porém, bugs também podem impactar a qualidade do serviço oferecido por um sistema, isto é, seus requisitos não funcionais, tais como segurança, desempenho, usabilidade, etc. Por exemplo, um bug pode fazer com que uma calculadora demore muito tempo (desempenho) para realizar certos cálculos.
Já o termo falha (failure) é usado para designar situações como a do exemplo acima, nas quais, devido a um bug (ou defeito), um programa não apresentou o comportamento externo esperado, seja ele funcional ou não funcional. Também é importante lembrar que certos bugs podem causar um crash, isto é, o término inesperado de um programa. Logo, um crash é um tipo específico de falha.
5.2 Tipos de Bugs 🔗
Como o leitor já deve estar imaginando, existe uma grande variedade de tipos de bugs. Porém, nesta seção, vamos destacar quatro tipos comuns e relevantes de bugs, que são bugs de gerenciamento de memória, bugs de concorrência, bugs de segurança e bugs causados por problemas de entendimento de requisitos.
5.2.1 Bugs de Memória 🔗
Bugs de memória são causados pelo uso incorreto, inseguro ou ineficiente da memória por parte de um programa. Eles ocorrem quando um programa aloca, libera ou acessa regiões de memória de forma inadequada, podendo levar a comportamentos inesperados, crashes e corrupção de dados. A seguir, descrevemos alguns tipos importantes de bugs de memória:
1. Vazamento de memória (memory leak): esse bug ocorre quando a memória é alocada, mas não é liberada. Logo, o programa pode abortar por falta de memória.
2. Uso de memória após sua liberação (use-after-free): esse bug ocorre quando se usa uma área de memória que já foi liberada e que possivelmente está sendo usada para outros fins. Isso pode causar sobrescrita de dados ou um crash.
3. Acesso a ponteiros NULL: quando se tenta acessar um ponteiro que possui o valor NULL, o que pode terminar o programa de forma inesperada.
4. Leitura de memória não inicializada: quando acessamos endereços de memória que ainda não foram inicializados. Logo, os resultados são imprevisíveis, pois não é possível inferir os valores que estão nos endereços acessados.
5. Buffer Overflow: quando se acessa um buffer (ou vetor ou outra estrutura similar) além do seu endereço final e, então, podemos sobrescrever outros dados do programa ou causar um crash. Existe um bug equivalente, chamado buffer underflow, que ocorre quando acessamos um buffer usando um índice ou ponteiro que referencia um endereço anterior ao seu endereço inicial.
6. Stack Overflow: quando a pilha onde ficam armazenadas as variáveis locais de um programa atinge seu tamanho máximo e não consegue armazenar novas variáveis locais. Isso pode ocorrer, por exemplo, devido a uma recursão infinita e o resultado desse bug será um crash.
Os bugs acima são mais comuns em linguagens como C e C++. Por outro lado, linguagens como Java, C#, Python e Go, dentre outras, foram projetadas para tornar o uso de memória mais seguro. Por exemplo, elas incluem mecanismos como coleta de lixo, que libera a memória automaticamente. Com isso, diminuem-se as chances de bugs causados por vazamentos de memória, por exemplo.
Além disso, em Java, os acessos aos índices de um vetor são sempre
verificados para garantir que estão dentro dos limites permitidos. Por
exemplo, não é possível acessar o índice 10 de um vetor cujos índices
variam de 0 a 9. Quando isso ocorre, lança-se uma exceção do tipo
ArrayIndexOutOfBoundsException. Ou seja, o programa pode
terminar com essa exceção, mas pelo menos não se permite acesso a uma
posição de memória inválida.
Mundo Real: Chromium é um projeto de código aberto, implementado em C++, e que serve como base para a implementação de navegadores Web como o Chrome. Na página do projeto, seus desenvolvedores resumem um estudo que fizeram com 912 bugs de severidade alta ou crítica do sistema reportados desde 2015 (link). Eles constataram que cerca de 70% desses bugs estão relacionados com o uso incorreto de memória. Dentre eles, os mais frequentes são causados por uso de memória após sua liberação (use-after-free), que corresponderam a cerca de metade dos bugs de memória. Esses percentuais reforçam então a relevância e preponderância de bugs de memória, principalmente em sistemas implementados em C e C++.
Aprofundamento: Em linguagens com coleta de lixo, como Java, C# e Go, é mais difícil ter vazamentos de memória, pois a memória é automaticamente liberada pelo coletor de lixo. Porém, em alguns casos, pode-se manter memória alocada por mais tempo do que seria necessário, o que leva alguns autores a considerarem que eles também constituem um vazamento de memória. Outros autores, como Joshua Bloch, sugerem chamar esses casos de retenção não intencional de objetos (unintentional object retentions). Por exemplo, isso pode acontecer quando um vetor estático referencia diversos objetos. Porém, alguns desses objetos, apesar de referenciados, não são mais usados no programa. Logo, estão ocupando memória de forma desnecessária, o que caracteriza um vazamento de memória (ou, pelo menos, tem as mesmas consequências que um vazamento em linguagens como C ou C++).
5.2.2 Bugs de Concorrência 🔗
Um segundo tipo de bug importante, e geralmente mais complexo, são bugs de concorrência. Eles ocorrem em programas com várias linhas de execução (threads), como é o caso do backend de aplicações distribuídas. Um bug de concorrência comum é conhecido pelo nome de condição de corrida (race condition) e ocorre quando várias threads acessam e modificam um mesmo conjunto de dados, sem que haja uma sincronização dessa escrita.
Por exemplo, suponha uma classe Contador, com apenas um
atributo do tipo inteiro, inicializado com zero, e com um método para
incrementá-lo:
class Contador {
private int valor = 0;
public void incrementar() {
valor++;
}
...
}Suponha ainda um programa principal que dispara duas threads. Ambas executam um laço que incrementa o contador 100 mil vezes.
public class Main {
public static void main(String[] args) {
Contador contador = new Contador();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100_000; i++) {
contador.incrementar();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100_000; i++) {
contador.incrementar();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
IO.println(contador.getValor());
}
}
Esse programa deveria imprimir como resposta o valor 200 mil. Porém, o acesso ao contador não é sincronizado. Suponha que o contador tenha, em um dado momento, o valor 1535. Então, ambas as threads podem ler esse valor (1535), incrementá-lo (1536) e escrever o resultado na memória. Logo, o valor final será 1536 e não 1537.
Para evitar esse bug, devemos sincronizar a execução do método
incrementar:
public synchronized void incrementar() {
valor++;
}
Agora, se uma thread começa a executar esse método, qualquer outra thread tem que esperar essa execução terminar para conseguir executá-lo. Ou seja, no nosso exemplo anterior, a primeira thread pode ler o valor do contador (1535), incrementá-lo (1536) e escrever o resultado na memória (1536). Só então a segunda thread consegue executar e ler o valor do contador (agora, 1536), incrementá-lo (1537) e salvar na memória.
Como o leitor deve estar percebendo, bugs de concorrência são mais complexos e, logo, tendem a levar mais tempo para serem corrigidos. Isso ocorre porque programas concorrentes não seguem um modelo de execução sequencial e determinístico. Em vez disso, eles são não determinísticos, isto é, a ordem de intercalação das instruções pelas threads pode variar de uma execução para outra. Por isso, ao executar o programa anterior cinco vezes na nossa máquina, na sua versão sem sincronização, os resultados foram sempre diferentes: 138397, 132279, 157933, 158299 e 142958. E, além de diferentes, todos os resultados foram incorretos!
Mundo Real: Um dos bugs de software mais estudados ocorreu na década de 1980, nos Estados Unidos e Canadá, envolvendo o software embutido em equipamentos de radioterapia, chamados de Therac-25. Dada a sua importância e consequências trágicas, ele ficou conhecido como Incidente do Therac-25. Basicamente, devido a bugs de concorrência, o software dessas máquinas, em determinadas situações, entrava em um estado inconsistente, permitindo que superdosagens de radiação fossem aplicadas nos pacientes, o que levou à morte de alguns deles. As causas do bug foram assim descritas em um dos principais artigos científicos que estudou o incidente, publicado por Leveson e Turner em 1993 (link):
Fica claro, a partir da documentação da AECL [fabricante dos equipamentos de radioterapia], que o software permite acesso concorrente a dados compartilhados, que não há sincronização e que as operações de
testesetdessas variáveis não são atômicas. Condições de corrida resultantes dessa implementação de concorrência desempenharam um papel importante nos acidentes.
No entanto, o incidente da Therac-25 ocorreu na década de 1980,
quando o conhecimento sobre bugs de concorrência ainda era limitado.
Atualmente, no entanto, a importância de evitar esses bugs,
sincronizando o acesso a dados compartilhados, é de amplo conhecimento.
Além disso, as principais linguagens de programação oferecem bibliotecas
para concorrência com diversos recursos para sincronização, como o
modificador synchronized existente em Java.
5.2.3 Bugs de Segurança 🔗
Como sistemas de software estão cada vez mais presentes nas atividades da nossa sociedade, não é uma surpresa que problemas de segurança se tornaram muito importantes também no mundo digital. Especificamente, bugs de segurança são defeitos que expõem um sistema a ataques, possibilitando acesso não autorizado, vazamento de dados e interrupção de serviços.
Mundo Real: Para reforçar a importância de bugs de segurança, vamos nos basear no número de registros do CVE (Common Vulnerabilities and Exposures), que é um repositório que documenta vulnerabilidades de segurança em sistemas de software e hardware (link). Em 2016, o sistema registrou 6.449 vulnerabilidades de segurança; já em 2025, esse número ultrapassou 48 mil vulnerabilidades, isto é, um aumento de mais de sete vezes.
Nota: Uma abordagem abrangente de problemas de segurança está fora do escopo deste livro. Em vez disso, nosso objetivo é apenas apresentar uma introdução aos principais tipos de bugs de segurança.
Algumas das principais causas de bugs de segurança incluem:
1. Falta de validação de entradas, isto é, quando dados fornecidos por usuários ou obtidos de sistemas externos não são verificados, possibilitando, por exemplo, ataques conhecidos como injeção de SQL. Seja o seguinte código:
String query =
"SELECT * FROM users WHERE name = '" + param + "'";
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(query);Assumindo que param é um dado de entrada, recebido, por
exemplo, de um formulário Web, pode ser que ele contenha,
maliciosamente, um segundo comando SQL (por exemplo,
DROP TABLE users). Logo, esse comando será concatenado na
consulta e executado pelo banco de dados, resultando na deleção da
tabela de usuários.
Como esse é um problema conhecido, bibliotecas para consultas SQL oferecem mecanismos para evitar injeção de comandos, como a seguir:
String query = "SELECT * FROM users WHERE name = ?";
PreparedStatement stmt = conn.prepareStatement(query);
stmt.setString(1, param);
ResultSet rs = stmt.executeQuery();Nesse novo código, primeiro definimos o comando SQL que queremos
executar e indicamos, por meio de um marcador (?), quais
valores serão fornecidos externamente. Em seguida, a consulta é
preparada, isto é, compilada para um formato interno do banco de dados.
Só depois os parâmetros são associados. Dessa forma, mesmo que os
parâmetros contenham um comando SQL, ele será tratado como um dado e não
como um valor executável.
De forma genérica, todo dado de entrada, fornecido por um usuário ou por um outro sistema, deve ser validado, para garantir que ele não representa uma ameaça ao funcionamento de um sistema. Essa prática faz parte de um estilo de desenvolvimento chamado de programação defensiva, conforme assim definido por Kernighan e Pike (link, página 114):
Programação defensiva, isto é, garantir que um programa não seja vulnerável a entradas inválidas, é importante tanto para proteger os usuários contra seus próprios erros quanto como um mecanismo de segurança.
Por exemplo, em um sistema acadêmico, ao receber a nota de uma prova como entrada, devemos garantir que ela seja um número real entre 0 e um valor máximo, com uma ou duas casas decimais. Da mesma forma, CEPs devem possuir cinco dígitos, seguidos de um hífen e mais três dígitos. Um raciocínio semelhante vale para preços, quantidades de produtos, datas, endereços de e-mail, números de telefone e quaisquer outros dados sujeitos a restrições de formato e de domínio. É importante também que essa validação não seja feita apenas no frontend. Isto é, mesmo que ela ocorra no frontend, é importante que ela seja repetida no backend, pois agentes maliciosos podem acessar o sistema diretamente via a API do backend.
Existe ainda o conceito de sanitização, que é um
pouco mais abrangente do que o de validação. Enquanto validar consiste
em determinar se o dado de entrada é válido ou não, uma sanitização pode
modificar e formatar o dado para garantir que ele seja válido e seguro.
Por exemplo, suponha que um sistema permita que usuários enviem
comentários em HTML. Se um usuário submeter o texto
<p>Olá</p><script>alert('hack')</script>,
uma rotina de sanitização pode remover a tag
<script>, preservando apenas
<p>Olá</p>.
Existem bibliotecas prontas para sanitização de dados. Por exemplo, o código a seguir usa a biblioteca OWASP Java HTML Sanitizer para remover conteúdo HTML potencialmente perigoso.
PolicyFactory policy = new HtmlPolicyBuilder()
.allowElements("p", "b", "i")
.toFactory();
String comment = request.getParameter("comment");
String safeComment = policy.sanitize(comment);
database.save(safeComment);Suponha que o comentário recebido como entrada tenha sido:
<p>Olá <b>mundo</b> <script>alert('hack')</script>
<i>seguro</i></p>Então, após a sanitização, o comentário efetivamente gravado no BD será:
<p>Olá <b>mundo</b> <i>seguro</i></p>Observe que, conforme a configuração da biblioteca, tags diferentes
de <p>, <b> e
<i> foram descartadas pela rotina de sanitização.
2. Armazenamento inseguro de senhas e chaves de API, por exemplo, quando esses valores são armazenados diretamente no código fonte, como no exemplo a seguir:
private static final String API_KEY = "7a9c3e1f4b8d2e6c...";
ServicoPagto servico = new ServicoPagto(API_KEY);
servico.pagar(valor);Esse código é problemático porque ele pode ser armazenado em um repositório compartilhado (por exemplo, no GitHub), tornando a chave da API visível para outros usuários. Uma alternativa segura é armazenar a senha ou a chave em uma variável de ambiente do sistema operacional e recuperar seu valor em tempo de execução, como no exemplo a seguir:
private static final String API_KEY =
System.getenv("API_KEY");
ServicoPagto servico = new ServicoPagto(API_KEY);
servico.pagar(valor);Por motivos semelhantes, senhas nunca devem ser salvas em formato textual em bancos de dados. O recomendado é sempre salvá-las na forma de hash, como no seguinte código.
PasswordEncoder pwdEncoder = new BCryptPasswordEncoder();
...
String senhaHash = pwdEncoder.encode(senhaEmTexto);
usuario.salvaSenha(senhaHash);
BCrypt é um algoritmo de hash específico para o armazenamento de
senhas. Em termos simples, ele transforma uma senha em um hash, sendo
que não é computacionalmente viável fazer o processo reverso (isto é,
recuperar a senha original a partir do hash). Já
BCryptPasswordEncoder é uma classe do Spring, um framework
muito popular no ecossistema de Java. Ela usa o algoritmo BCrypt para
gerar e verificar hashes de senhas. No momento do login, para verificar
se a senha informada por um usuário é válida, podemos usar um código
como o seguinte:
passwordEncoder.matches(senhaInformada, usuario.getSenha());
3. Dependências Vulneráveis: No entanto, muitas vezes o bug não está no código de um sistema, mas nas bibliotecas e frameworks que ele usa. Por isso, é importante verificar a credibilidade da organização responsável por cada dependência externa do seu sistema e, possivelmente, o número de usuários da mesma e a frequência de novas releases. Além disso, deve-se manter as dependências atualizadas, para rapidamente tirar proveito de correções de problemas de segurança.
Mundo Real: A Equifax é uma empresa americana de análise de crédito (semelhante, por exemplo, à Serasa, no Brasil). Na implementação dos seus sistemas, a empresa usava o framework Apache Struts. Em 2017, uma vulnerabilidade crítica de segurança foi identificada nesse framework, documentada como CVE-2017-5638, e uma correção de segurança foi disponibilizada. No entanto, a Equifax não aplicou a correção e continuou usando a versão vulnerável do Struts. Como consequência, seus sistemas foram invadidos por hackers que tiveram acesso aos dados de mais de 147 milhões de pessoas, incluindo, em alguns casos, números de cartões de crédito.
Também não podemos nos esquecer de que dependências de software são transitivas. Isto é, se o seu sistema depende de uma biblioteca B, que por sua vez depende de uma biblioteca C, então uma vulnerabilidade em C pode afetar o seu sistema. Esse problema é conhecido como vulnerabilidade na cadeia de suprimentos de software (software supply chain vulnerability). O termo é inspirado na cadeia de suprimentos de indústrias físicas. Por exemplo, uma montadora de automóveis adquire peças de diversos fornecedores, que, por sua vez, também dependem de outros fornecedores, e assim por diante. Um problema em qualquer elo dessa cadeia pode comprometer a qualidade dos automóveis produzidos pela montadora, inclusive em aspectos críticos de segurança.
Mundo Real: Um dos mais graves exemplos de ataque à cadeia de suprimentos de software ocorreu em um sistema de gerenciamento de redes desenvolvido pela empresa norte-americana SolarWinds. Em 2020, atacantes conseguiram comprometer o processo de compilação desse sistema. Especificamente, eles conseguiram adicionar na base de código do sistema um módulo malicioso. Como resultado, as releases oficiais do software passaram a incluir esse código adulterado, que foi distribuído como uma atualização legítima. Uma vez instalado, o código malicioso permitia o acesso não autorizado a informações sensíveis, como credenciais e dados internos dos clientes. Entre as organizações afetadas estavam grandes empresas e órgãos do governo dos Estados Unidos. Logo, os hackers alteraram o sistema não com o intuito de acessar dados da SolarWinds, mas sim de terceiros que viessem a instalar o sistema dessa empresa. Outra reflexão sobre esse caso é que normalmente recomenda-se manter um sistema atualizado para tirar proveito de atualizações de segurança. No entanto, no episódio em questão, um cliente da SolarWinds se tornava vulnerável exatamente por atualizar o seu sistema para a nova versão (que continha infiltrado um código malicioso). Portanto, esse episódio é também um exemplo da complexidade e abrangência de problemas de segurança.
5.2.4 Bugs de Entendimento de Requisitos 🔗
Esses bugs ocorrem quando desenvolvedores não entendem corretamente os requisitos de um sistema. Ou seja, a causa raiz do bug não está em um problema de implementação, mas em um entendimento incorreto ou incompleto do que deveria ser implementado.
Suponha que em um sistema de comércio eletrônico pagamentos à vista devem ter um desconto de 10% (para clientes normais) ou de 12% (para clientes especiais). Porém, o desenvolvedor responsável por essa parte do sistema não estava ciente dessas categorias de desconto — por exemplo, devido a uma falha de comunicação com o Product Owner (PO) ou com o Product Manager (PM) — e implementou um único desconto de 10% para todos os clientes. Logo, ele introduziu um bug cuja causa raiz não está no código, mas no desconhecimento das categorias de desconto do sistema.
Esses bugs também ocorrem quando casos de contorno (edge ou corner cases) não são devidamente tratados. Tais casos representam situações específicas ou exceções a uma regra geral. No nosso sistema de comércio eletrônico, um exemplo de caso de contorno pode ser o seguinte: apenas no estado de Minas Gerais (hipoteticamente) o imposto considera o valor do frete, enquanto nos demais estados o imposto incide apenas sobre o valor dos produtos. Logo, o desenvolvedor — em interações com o PO — deve tomar conhecimento desse caso de contorno e considerá-lo no seu código.
Outros exemplos de casos de contorno envolvem valores de entrada nas fronteiras dos valores válidos. Por exemplo, suponha que compras iguais ou acima de R$ 500,00 possuem frete grátis. Logo, o desenvolvedor deve validar esses limites com o PO, de forma a não implementar a gratuidade do frete apenas para compras acima de R$ 500,00. Se o requisito for mais complexo, pode ser interessante criar um documento de requisitos, para dar mais clareza ao que deve ser implementado.
Para que bugs de entendimento de requisitos não cheguem em produção, reuniões de revisão ao final de cada sprint devem ser realizadas de forma criteriosa (em Scrum, tais reuniões são chamadas de Sprint Reviews). Nelas, o resultado do sprint é mostrado para o PO/PM e para outros usuários importantes. Então, ao testar o resultado do sprint, eles podem detectar que um determinado requisito não foi implementado da forma correta.
Testes manuais, realizados por profissionais de qualidade, como QAs (Quality Assurance), ou mesmo por PO e PMs também ajudam a detectar esses bugs. Especificamente, testes exploratórios são úteis nesses contextos. Neles, um testador executa um sistema com um maior grau de liberdade, sem seguir um roteiro detalhado de passos e entradas. Em vez disso, ele usa sua experiência e conhecimento do domínio para verificar o comportamento do sistema, principalmente em casos de contorno ou cenários específicos.
Literatura Científica: Existe uma vasta literatura
sobre a importância e os altos custos associados à correção de bugs
decorrentes de problemas no entendimento de requisitos. Por exemplo,
Barry Boehm e Victor Basili, em um artigo publicado em 2001, já
afirmavam o seguinte: encontrar e corrigir um problema de software
após a entrega pode ser até 100 vezes mais caro do que encontrá-lo e
corrigi-lo durante as fases de requisitos e projeto
(link). Robert Glass também
já publicou um livro relevante sobre fatos (isto é, verdades
fundamentais) em Engenharia de Software. Dentre os 55 fatos que ele
lista, dois estão diretamente relacionados com requisitos:
Bugs de requisitos são os mais caros de corrigir quando descobertos em produção, mas os mais baratos quando identificados nas fases iniciais do desenvolvimento
.Requisitos ausentes são os bugs de requisitos mais difíceis de corrigir
.
Essas afirmações e estudos, de pesquisadores conhecidos, apenas reforçam a importância de atividades de levantamento e entendimento dos requisitos de um sistema.
5.2.5 Outros Tipos de Bugs 🔗
Um bug muito comum e simples, mas que pode ter grande impacto, é conhecido como off-by-one. Ele é causado por um desvio de uma unidade, para mais ou para menos, na condição de término de um laço (ou em qualquer outra condição de um programa). Como exemplo, considere o programa a seguir:
int[] vetor = {10, 20, 30};
for (int i = 0; i <= vetor.length; i++) { // bug
IO.println(vetor[i]);
}Nesse caso, o bug ocorre porque a condição de término do
for é inclusiva (<=), quando deveria ser exclusiva
(<), fazendo com que o laço tente acessar uma posição inválida do
vetor.
Na Seção 5.2.3 já tratamos de bugs de segurança, mas existem também bugs relacionados com outros requisitos não funcionais, incluindo:
Bugs de desempenho: o sistema funciona, mas possui um tempo de resposta muito alto. Por exemplo, algumas operações levam muito tempo para serem processadas. Pode ocorrer também de o sistema funcionar com pouca carga, mas não conseguir escalar quando essa carga aumenta.
Bugs de usabilidade: o sistema possui uma interface com o usuário que dificulta seu uso, por exemplo, com mensagens de erro obscuras ou inexistentes, menus confusos ou com muitas opções, esquemas de cores que dificultam a visualização, problemas de acessibilidade, etc.
Bugs de compatibilidade: o sistema funciona somente em algumas plataformas ou com bibliotecas específicas. Por exemplo, um sistema somente funciona no navegador Mozilla Firefox. Ou um outro sistema somente funciona em Python 2.7 ou anterior.
5.2.6 Perguntas Frequentes 🔗
Seguem algumas perguntas frequentes sobre tipos de bugs.
Podem existir interações entre os tipos de bugs tratados
nesta seção? Sim, também é possível. Um caso comum é uma
vulnerabilidade de segurança que se vale de um buffer overflow (isto é,
um bug de memória). Nesses casos, os atacantes podem aproveitar o
overflow para corromper áreas de memória que excedem
àquelas de
um buffer. E então eles podem conseguir modificar o comportamento do
programa. Por exemplo, eles podem mudar o endereço de retorno de uma
função, para que ela, ao retornar, execute um código malicioso.
O que é uma regressão? Uma regressão ocorre quando
uma modificação no código de um sistema — seja para corrigir um bug,
adicionar uma nova funcionalidade ou realizar uma refatoração — introduz
um bug. Em outras palavras, o sistema anda para trás
: algo que
estava funcionando passa a falhar após a modificação. Na verdade,
regressões são um problema conhecido em Manutenção de Software. No seu
livro clássico sobre projeto de Software (The Mythical
Man-Month, 1975), o Prof. Frederick Brooks já afirmava: o
problema fundamental da manutenção de programas é que corrigir um
defeito tem uma probabilidade significativa (20–50%) de introduzir
outro. Assim, todo o processo é como dar dois passos à frente e um passo
atrás.
5.3 Ferramentas para Detecção de Bugs 🔗
Existem ferramentas que tentam desempenhar uma tarefa de grande importância: detectar bugs de forma automática. Nesta seção, vamos estudar dois tipos de ferramentas com esse propósito: ferramentas baseadas em análise estática e ferramentas para detectar dependências vulneráveis. Além de apresentar as ferramentas, vamos também discutir suas limitações.
5.3.1 Ferramentas de Análise Estática 🔗
Essas ferramentas se valem apenas do código fonte para detectar bugs. Daí o adjetivo estático no nome, que enfatiza que elas não requerem a execução do código analisado. Praticamente toda linguagem de programação possui ferramentas com esse propósito, incluindo soluções de código aberto e comerciais. Como exemplo de ferramenta com uma versão comercial, podemos citar o SonarQube (que suporta diversas linguagens de programação); como exemplo de ferramenta de código aberto, podemos citar o SpotBugs (anteriormente chamado de FindBugs, para Java). Embora não explicitamente mencionadas aqui, o leitor poderá facilmente encontrar ferramentas semelhantes para sua linguagem de preferência.
Vamos dividir nossa explicação sobre o funcionamento de ferramentas de análise estática em duas partes: casos de sucesso (que costumamos chamar de verdadeiros positivos) e casos de insucesso (que podem ser falsos negativos ou falsos positivos).
Verdadeiros Positivos: A seguir, mostramos um exemplo de bug que ferramentas de análise estática são capazes de detectar e que são mesmo bugs. Ou seja, trata-se de um resultado positivo (bug encontrado) e verdadeiro. Vamos primeiro mostrar o programa:
class Aluno {
String nome;
}
public class App {
static void printNomeAluno(Aluno aluno) {
IO.println(aluno.nome);
}
public static void main(String[] args) {
printNomeAluno(null);
}
}
Ao ser executado, esse programa termina com uma
NullPointerException na linha do IO.println.
Uma ferramenta como SpotBugs consegue detectar esse bug estaticamente e
dar o seguinte aviso:
Method call in App.main(String[]) passes null for non-null parameter of
printNomeAluno(Aluno) at App.java: [line 10]
Essa mensagem alerta que o método printNomeAluno é
chamado na linha 10 usando null como parâmetro, o que não é
válido no caso desse método.
Esse exemplo é muito simples e possui apenas fins didáticos. E o próprio desenvolvedor poderia executar o programa e descobrir o bug, sem precisar usar uma outra ferramenta. Porém, pode ser bem mais difícil executar e testar um sistema grande, com diversas entradas e ter que navegar por muitas páginas, até conseguir reproduzir um bug. Já com análise estática o desenvolvedor precisa apenas usar uma segunda ferramenta, além do compilador.
Como exemplos de outros bugs que ferramentas de análise estática
podem detectar podemos mencionar: loops infinitos, variáveis que são
usadas antes de serem inicializadas, acesso a vetores fora dos limites
permitidos, divisão por zero, arquivos ou conexões que são abertos, mas
que não são fechados, dentre outros. Logo, podemos perceber que são
problemas pontuais
e que violam regras básicas de uma linguagem
de programação.
Falsos Negativos: Vamos agora falar de uma primeira limitação. Como ferramentas de análise estática analisam apenas o código, elas não conhecem os requisitos do sistema que estão analisando. Por isso, elas estão sujeitas a muitos falsos negativos, isto é, uma análise com resultado negativo para ocorrência de bugs pode ser falsa. Em outras palavras, a ferramenta informa que o sistema não tem bugs, mas ele tem, tal como no seguinte exemplo de uma função para somar os inteiros de 1 a n.
int somaInteiros(int n) {
int soma = 0;
for (int i = 1; i < n; i++) { // bug
soma += i;
}
return soma;
}
Esse código possui um bug do tipo off-by-one, pois a condição final
do for deveria ser i <= n. Porém, como esse
bug está relacionado com um requisito do programa (calcular o somatório
dos inteiros de 1 a n), uma ferramenta de análise estática não
conhece detectá-lo.
Falsos Positivos: Esses casos representam uma
segunda limitação de ferramentas de análise estática. Eles ocorrem
quando a ferramenta emite um alarme (o sistema tem bugs
), mas ele
é falso. Ou seja, o código, de fato, não possui nenhum bug.
Em geral, falsos positivos ocorrem porque certas regras verificadas por ferramentas de análise estática possuem um grau de subjetividade. Ou seja, a violação da regra não implica, necessariamente, em um bug real. Seguem alguns exemplos de regras do SpotBugs com esse perfil:
Código que compara strings usando
==, em vez deequals.Uma expressão com condição redundante, como
(x == 0) || (x == 0).Um método
equalsque sempre retornatrue.Um método chamado
tostring()em vez detoString().
No primeiro caso, pode ser intencional comparar strings usando seus
endereços (==) e não seus valores (equals). A
segunda regra representa uma redundância, mas ela não altera o
comportamento funcional do programa. Já a terceira regra pode não se
aplicar a cenários específicos. A última regra é uma boa recomendação,
mas seu descumprimento não necessariamente implica em um resultado
incorreto.
Por isso, ao usar qualquer ferramenta de análise estática, é
importante configurá-la cuidadosamente, selecionando apenas as regras
que são importantes no seu projeto. Um erro comum é começar a usar esse
tipo de ferramenta em um sistema muito grande e legado. Nesses casos, a
ferramenta vai identificar centenas ou até milhares de problemas, muitos
dos quais serão falsos positivos. Isso pode gerar a impressão de que a
ferramenta não é útil, já que os desenvolvedores vão perder tempo
analisando alertas irrelevantes. No limite, eles podem decidir abandonar
a ferramenta. Por isso, é fundamental que a adoção de ferramentas de
análise estática comece com um conjunto reduzido de regras. Por exemplo,
devemos configurar a ferramenta para apenas considerar regras com
grandes chances de detectar bugs verdadeiros, como a exceção do tipo
NullPointerException do nosso primeiro exemplo.
5.3.2 Ferramentas para Detectar Dependências Vulneráveis 🔗
Devido ao aumento dos problemas causados por dependências desatualizadas, tal como comentamos na Seção 5.2.3, existem também ferramentas que monitoram as dependências de um projeto e emitem alertas quando detectam uma dependência com uma vulnerabilidade de segurança relevante. Por exemplo, o GitHub oferece uma ferramenta chamada Dependabot, que identifica dependências vulneráveis e abre um Pull Request (PR) sugerindo a atualização para uma versão segura da dependência. Essa ferramenta pode ser configurada para rodar em intervalos regulares (por exemplo, diariamente) ou então por demanda.
Suponha que o Dependabot existisse na época do episódio da Equifax
(também comentado na Seção 5.2.3) e que a empresa estivesse usando essa
ferramenta. Nesse caso, o Dependabot teria sido capaz de detectar o uso
de uma versão vulnerável do Apache Struts (por exemplo, a versão 2.3.31)
e teria aberto automaticamente um PR atualizando essa dependência para
uma versão segura (por exemplo, 2.3.32). Essa correção modificaria o
arquivo pom.xml, conforme abaixo:
- <dependency>
- <groupId>org.apache.struts</groupId>
- <artifactId>struts2-core</artifactId>
- <version>2.3.31</version>
- </dependency>
+ <dependency>
+ <groupId>org.apache.struts</groupId>
+ <artifactId>struts2-core</artifactId>
+ <version>2.3.32</version>
+ </dependency>O arquivo pom.xml é o arquivo de configuração principal
do Maven, que é a ferramenta mais usada para gerenciamento de
dependências em projetos Java. Apesar de o exemplo ser para Java, o
Dependabot funciona com gerenciadores de dependências de outras
linguagens, como npm (JavaScript), pip (Python) e RubyGems.
5.3.3 Perguntas Frequentes 🔗
Seguem algumas perguntas sobre ferramentas de análise estática:
O que é um linter? Ferramentas de análise estática para detecção de bugs são muitas vezes chamadas de linters. O nome deriva daquela que provavelmente foi a primeira ferramenta com esse propósito, criada em 1978, por Stephen Johnson, para a linguagem C. Na época, ele decidiu chamar a sua ferramenta de lint. Daí em diante, ferramentas com objetivos semelhantes são frequentemente chamadas de linters.
Existem ferramentas de análise estática com mais de um objetivo? Sim, existem ferramentas que são verificadores de estilos (tal como vimos na Seção 2.3), detectores de bugs e também de dependências vulneráveis, dentre outras tarefas.
Quando ferramentas de análise estática devem ser executadas? A resposta é o mais cedo possível. Por exemplo, após cada compilação ou build do sistema. Outra possibilidade é a execução pelo servidor de integração contínua. O ideal é que o feedback dessas ferramentas seja passado aos desenvolvedores o quanto antes, enquanto a mudança de código está fresca na cabeça deles. Depois que o código estiver integrado no repositório principal, os desenvolvedores vão começar outra tarefa e, portanto, vão estar menos suscetíveis a analisar os alertas gerados por uma ferramenta de análise estática.
Ferramentas de análise estática podem ser usadas para ajudar a corrigir bugs reportados por usuários finais de um sistema? Sim, podem, pois toda ajuda é válida quando se tem que descobrir a causa de um bug, como veremos no próximo capítulo. Porém, temos que reforçar a resposta anterior: essas ferramentas são mais efetivas para evitar, prematuramente, a introdução de bugs em um sistema. Se usadas tardiamente, elas vão gerar muitos falsos positivos e, portanto, o seu custo/benefício pode começar a ser questionado.
Qual a taxa máxima de falsos positivos que deve ser tolerada? É difícil definir um valor exato e universal. Porém, em alguns artigos publicados por desenvolvedores do Google, sugere-se um limiar de 10% para falsos positivos, assumindo que as ferramentas são executadas por servidores de CI (link). Portanto, se uma determinada regra gerar mais de 10% de falsos positivos, ela deve ser desabilitada.
5.4 Sistemas de Rastreamento de Bugs 🔗
Quando um bug é detectado por um usuário de um sistema, ele deve ser reportado. Para isso, deve-se usar um sistema de rastreamento de bugs (bug tracking system). Dentre os sistemas que existem com esse propósito, podemos citar: Bugzilla, Jira, Mantis, Redmine e Linear. Sistemas de controle de versões, como o GitHub e GitLab, também oferecem recursos para rastreamento de bugs. De todo modo, o importante é que exista um sistema para centralizar e acompanhar o ciclo de vida de qualquer bug, desde o seu registro por parte de um usuário até a sua correção.
O principal recurso oferecido por sistemas de rastreamento de bugs é um formulário, por meio do qual usuários dão mais informações sobre o bug que encontraram no sistema. Dentre os campos mais importantes de tais formulários, podemos citar:
Título do bug, opcionalmente, acompanhado de uma breve descrição.
Versão e plataforma na qual o bug foi detectado.
Passos para reproduzir o bug, que podem incluir screenshots ou trechos de código (se o bug ocorreu em uma biblioteca ou framework).
Comportamento esperado do sistema, ou seja, resultado esperado, caso o bug não existisse.
Comportamento observado no sistema, isto é, o resultado incorreto causado pela existência do bug. Deve-se informar também se o bug acontece sempre, ou se ele é um bug intermitente.
Segue um exemplo, assumindo um bug em um sistema de comércio eletrônico:
Título: Cupom de desconto aplicado no preço com frete
Versão e plataforma: Versão 3.5, com Windows 11 e Chrome 143.
Passos para reprodução: Logar no sistema como usuário autenticado. Adicionar dois ou três produtos no carrinho. Aplicar o cupom DESC10. Ir para a página de checkout.
Comportamento esperado: O sistema deve aplicar o desconto de 10% sobre o valor dos produtos do carrinho, sem considerar o frete. Exemplo: se R$ 200 de produtos e R$ 15 de frete, o valor final correto é (200 * 0.9) + 15 = R$ 195.
Comportamento observado: O sistema aplica o desconto de 10% no preço total mais o frete. Para o exemplo anterior, o sistema está calculando incorretamente o valor final de (200 + 15) * 0.9 = R$ 193.50.
Observação: o bug ocorre sempre, para qualquer carrinho e cupons válidos.
5.4.1 Boas Práticas para Reportar Bugs 🔗
Quando um desenvolvedor vai corrigir um bug, primeiro ele tem que reproduzir esse bug. Portanto, os seguintes campos são essenciais quando se reporta um bug: passos para reprodução, comportamento esperado e comportamento observado.
Esses campos devem ser preenchidos de forma objetiva, não ambígua e resumida. Em outras palavras, se você quer que um bug seja corrigido rapidamente, invista tempo no preenchimento do formulário de bugs. Tente dar as informações exatas — isto é, nem para mais, nem para menos — que um desenvolvedor vai precisar para reproduzir o seu bug.
Caso esteja reportando bug em uma biblioteca ou framework, é importante que anexe um exemplo de código, que use a biblioteca ou framework e cuja execução resulte em um bug. O acrônimo SSCE resume as propriedades que esses exemplos de código devem possuir:
- Short, isto é, menor código possível.
- Self-contained, isto é, ter o mínimo de dependências externas; o ideal é que o desenvolvedor consiga copiar, colar e rodar seu código, e reproduzir o bug.
- Correct, isto é, não possuir erros de compilação; respeitar os guias de estilo do projeto e incluir comentários, se forem úteis.
- Ser um exemplo (Example) que realmente confirme o bug.
Existem também siglas similares, como MRE (Minimal, Reproducible Example), MCVE (Minimal, Complete, and Verifiable Example) e MWE (Minimal, Workable Example).
5.4.2 Perguntas Frequentes 🔗
Sistemas de rastreamento de bugs podem ser usados para gerenciar outras tarefas? Sim, é muito comum que o escopo desses sistemas seja expandido e eles sejam usados para gerenciar, por exemplo, a implementação de histórias de usuários (isto é, de novas funcionalidades). Quando isso acontece, eles são chamados de sistemas de gerenciamento de issues.
5.5 Ciclo de Vida de Bugs 🔗
Até este momento, já comentamos sobre os principais tipos de bugs, bem como sobre a importância de reportar bugs de forma bastante clara. Agora, vamos tratar das etapas que um bug deve seguir até ser corrigido, começando pela etapa de triagem, depois pela correção propriamente dita e, por fim, por eventuais retrabalhos que sejam necessários. Antes de continuar, queremos dizer, no entanto, que as fases e estados que descreveremos a seguir podem variar, dependendo da organização. Por isso, nosso objetivo é prover um entendimento abrangente, embora não necessariamente exaustivo e padronizado, do ciclo de vida de um bug.
5.5.1 Triagem 🔗
Quando um bug é reportado ainda não temos certeza de que ele de fato existe. Por isso, o bug entra em uma lista de bugs abertos (opened). Em algum momento, o formulário que descreve o bug será lido e analisado por especialistas no domínio do sistema ou por profissionais de desenvolvimento ou qualidade de software. Esse processo é chamado de triagem e tem como objetivo confirmar se o bug existe, conforme ilustrado na próxima figura.

Se o resultado da triagem for positivo, o bug passa para um estado confirmado (confirmed). Isso pode ser feito adicionando um rótulo (label) ao bug. Portanto, o bug existe e iremos corrigi-lo. Neste momento, o responsável pela triagem pode também adicionar novas informações no formulário do bug, como a sua severidade e componente do sistema afetado pelo bug.
No entanto, a triagem pode também determinar que o bug não será corrigido. Logo, ele deve ser movido para uma lista de bugs fechados (closed), mas com um rótulo adicional que indica o motivo da não confirmação. Dentre os motivos para não confirmar um bug, podemos citar:
Bug duplicado (closed as duplicate), ou seja, o bug já foi reportado.
Bug é um pedido de feature ou suporte (closed as invalid).
Bug não possui descrição clara (closed as incomplete).
Bug não foi reproduzido (closed as worksforme)
Bug existe, mas não será corrigido (closed as wontfix). Por exemplo, o bug não é relevante, tal como um problema mínimo de leiaute que afeta minimamente o funcionamento do sistema apenas em uma versão antiga do Android.
5.5.2 Fluxo de Correção 🔗
A próxima figura descreve os passos para correção de um bug. Após ser confirmado na triagem, o bug deve ser atribuído (assigned) a um desenvolvedor. Normalmente, sistemas de rastreamento de bugs oferecem um recurso para realizar essa atribuição. Esse desenvolvedor será então responsável por trabalhar na correção do bug.

Quando o desenvolvedor terminar de corrigir o bug, ele deve abrir um
Pull Request (PR), que é uma solicitação para que o código com a
correção seja integrado ao repositório do projeto. Ele deve também
associar esse PR ao identificador (número) do bug que está resolvendo.
Essa associação pode ser feita usando uma opção do sistema de
rastreamento de bugs ou, em muitos casos, basta incluir a seguinte linha
na descrição do PR: fixes #bug-id.
Em seguida, em muitas organizações, o código deve ser revisado por pelo menos um outro desenvolvedor, que vai verificar se a correção está correta e atende aos padrões técnicos do sistema. Se estiver, o revisor pode aceitar o PR e integrar (merge) o código no branch principal do repositório. Consequentemente, o bug associado ao PR será automaticamente movido para a lista de bugs fechados (closed) como corrigidos (fixed).
5.5.3 Retrabalho 🔗
Qualquer uma das decisões mencionadas acima pode se revelar errada. Por exemplo, uma triagem pode decidir que o bug é duplicado, mas na verdade ele não é (pois um usuário voltou a reportar o bug e uma nova triagem concluiu que ele é um bug novo). Assim, dessa vez, o bug deverá ser confirmado e entrar em um fluxo de correção. Isso é considerado um retrabalho porque o bug passou por duas triagens.
Existem também outros casos de retrabalho. Por exemplo, um bug foi corrigido por um desenvolvedor, mas um revisor, ao revisar o PR submetido, identificou que a correção não segue algum padrão ou convenção do projeto. Logo, a proposta de correção deve ser modificada pelo primeiro desenvolvedor e o PR deve ser atualizado, a fim de atender tal padrão. Então, ele será reavaliado e, possivelmente, aceito.
Como um último exemplo, um desenvolvedor pode corrigir um bug, submeter um PR, ele ser revisado e o bug ser fechado como corrigido. No entanto, um usuário detecta que a correção não está correta e decide reportar o bug de novo. Nesse caso, é necessário uma nova triagem, que vai concluir que se trata de um problema em um bug fechado. Logo, deve-se reabrir esse bug e ele vai entrar novamente em um fluxo de correção.
Literatura Científica: Infelizmente, reabertura de bugs não é um evento raro. Em 2013, Emad Shihab e colegas realizaram um estudo com três sistemas de código aberto: Eclipse, Apache HTTP e OpenOffice (link). Eles rastrearam um grande conjunto de bugs de cada sistema e concluíram que o percentual de bugs reabertos não é desprezível: 16% (Eclipse), 6% (Apache HTTP) e 26% (OpenOffice). Portanto, esses percentuais mostram a importância de práticas de verificação e revisão de código, notadamente quando se trata de marcar um bug como fechado e corrigido.
5.5.4 Backporting 🔗
Muitos sistemas de software possuem apenas uma versão em produção. Por exemplo, isso ocorre quase sempre com sistemas Web. Por outro lado, também existem muitos sistemas que possuem várias versões em produção, tal como sistemas operacionais, compiladores, bibliotecas e frameworks dos mais diversos tipos e também sistemas que são customizados para um determinado cliente. Então, se um sistema possui várias versões em produção, quando se corrige um bug, a correção deve ser aplicada, pelo menos, em algumas dessas versões. Suponha que corrigimos um bug em sistema cuja versão mais recente é x. Então, chamamos de backporting a tarefa de aplicar a mesma correção no código de versões anteriores a x que estão em produção e que possuem usuários.
Por outro lado, sistemas de software podem durar décadas, como vimos
no Capítulo 1. Assim, a tarefa de backporting normalmente fica restrita
a bugs mais importantes e críticos, como bugs de segurança.
Adicionalmente, define-se um intervalo de tempo para que uma versão
antiga continue recebendo correções de bugs. Por exemplo, podemos
definir que versões normais
vão receber correções de bugs pelo
período de um ano e que algumas versões específicas terão correção de
bugs por três anos, por exemplo. Essas últimas versões são chamadas de
versões com Long-Term Support
(LTS).
Exemplo: O Django é um framework para desenvolvimento de aplicações web em Python. Atualmente, ele adota um ciclo padronizado de lançamento de versões: as versões LTS recebem 36 meses de suporte, enquanto as demais versões recebem 16 meses. Uma nova versão LTS é lançada a cada 24 meses, e versões não LTS são lançadas a cada 8 meses. Já no caso do Linux, as versões LTS do kernel não seguem um calendário de lançamento pré-definido. Dentre os critérios para definir que uma versão será LTS incluem-se a presença de funcionalidades relevantes, demandas de fabricantes de dispositivos e a carga de trabalho dos desenvolvedores do kernel.
Bibliografia 🔗
Diomidis Spinellis. Code Quality: The Open Source Perspective. 2006.
Charles Pfleeger, Shari Lawrence Pfleeger, Lizzie Coles-Kemp. Security in Computing, 6th edition, Pearson, 2025.
Henrique Rocha, Guilherme de Oliveira, Humberto Marques-Neto, Marco Tulio Valente. Characterizing Bug Workflows in Mozilla Firefox. In 30th Brazilian Symposium on Software Engineering (SBES), 2016.
Exercícios 🔗
1. Descreva dois bugs de memória no código abaixo em C. Classifique esses bugs de acordo com os tipos de bugs de memória discutidos na Seção 5.2.1.
int *createArray(int n) {
int *v = (int *) malloc(n * sizeof(int));
for (int i = 0; i <= n; i++) {
v[i] = i;
}
return v;
}
void f() {
int *a = createArray(10);
printf("%d\n", a[5]);
free(a);
printf("%d\n", a[6]);
}2. Qual é o bug de memória que existe no seguinte programa C?
int main() {
char nome[10];
int id = 1234;
strcpy(nome, "Maria Jose");
printf("Nome: %s\n", nome);
printf("ID: %d\n", id);
}3. Pesquise e defina o conceito de dangling pointer (ponteiro pendurado). Ele está associado a qual tipo de bug de memória?
4. Seja a seguinte implementação da função abs em
Java:
public static int abs(int a) {
return (a < 0) ? -a : a;
}De forma interessante, se chamarmos
Math.abs(Integer.MIN_VALUE)o resultado será também Integer.MIN_VALUE.
Pesquise e explique por que isso acontece. Para isso, consulte a documentação do método.
Esse resultado é um bug da implementação de
absem Java? Justifique.
5. Em 2014, um bug crítico de segurança afetou os sistemas iOS e macOS da Apple. Esse bug fazia com que a verificação de certificados SSL/TLS fosse ignorada, permitindo que atacantes realizassem ataques mesmo em conexões HTTPS. Como consequência, tráfego supostamente seguro podia ser interceptado, lido e modificado por terceiros. Ele ficou conhecido pelo nome goto fail (CVE-2014-1266) e ocorreu no seguinte código (editado e tornado mais simples para fins deste exercício):
#define OK 0
#define ERROR 1
int validateServerCertificate() {
int err = OK;
if ((err = checkStep1()) != 0)
goto fail;
if ((err = checkStep2()) != 0)
goto fail;
goto fail; // bug
if ((err = checkStep3()) != 0)
goto fail;
/* sucesso */
err = OK;
fail:
return err;
}Explique o comportamento incorreto causado pela linha extra
goto fail.Discuta como esse bug pode ter sido introduzido no código.
Discuta como esse bug poderia ter sido evitado.
6. Por que testes de unidade não são adequados para tratar bugs causados por um entendimento incorreto ou incompleto de requisitos funcionais?
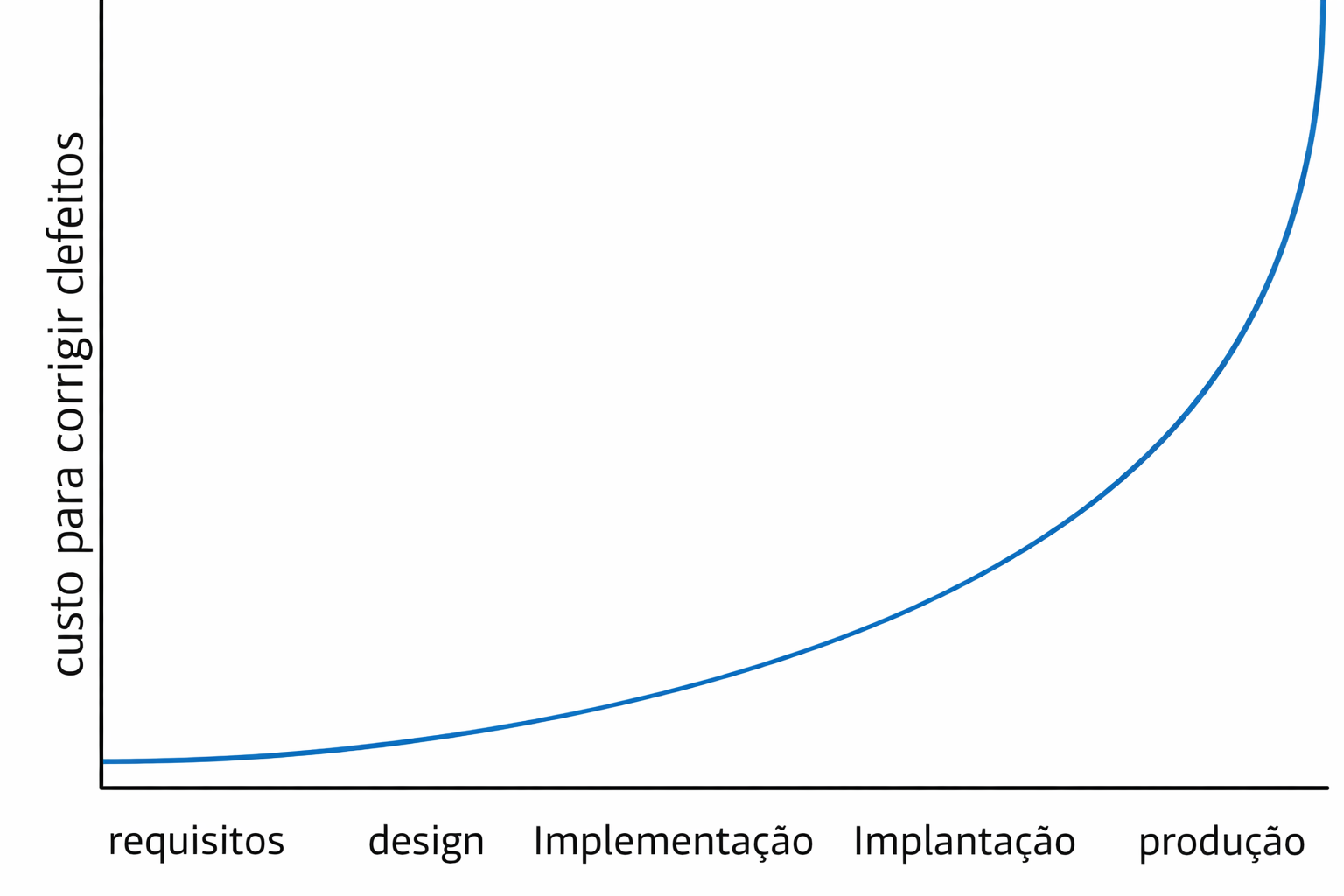
7. A curva mostrada a seguir é muito famosa em artigos e livros de
Engenharia de Software. Ela, normalmente, é usada para justificar um
conjunto de práticas conhecido como shift-left
. Faça uma breve
interpretação dessa curva. Qual tipo de bug tende a ser melhor
representado por ela? Justifique.
8. Linters podem ser muito úteis para detectar bugs. Porém, muitas vezes essas ferramentas possuem uma má reputação entre desenvolvedores. Explique por que isso acontece e recomende duas boas práticas para usar linters de forma efetiva em manutenção de software.